Both HMMs and LDS capture temporal dynamics in latent-variable models, but each has a fundamental limitation. An HMM assumes the hidden state is discrete — it can represent switching behaviour but cannot track smoothly evolving continuous quantities. An LDS assumes a single linear Gaussian regime — it can track smooth continuous dynamics but cannot represent abrupt regime changes.
A switching linear dynamical system (SLDS) combines both: a discrete chain that selects which linear regime is active at each step, and a continuous chain whose dynamics depend on that regime. The model can represent a system that moves smoothly within each regime but switches sharply between them.
Topics covered:
The SLDS generative model
Why exact EM is intractable: forward messages are exponential mixtures
Structured mean-field variational inference: alternating HMM and Kalman updates
Recurrent SLDS and Variational Laplace EM
import torch
import torch.distributions as dist
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import numpy as np
palette = list(plt.cm.tab10.colors)
torch.manual_seed(305)<torch._C.Generator at 0x7fc6d8f0c5d0>The SLDS Generative Model¶
An SLDS has three layers of latent structure:
| Layer | Variable | Role |
|---|---|---|
| Discrete chain | Which dynamical regime is active | |
| Continuous chain | Continuously evolving latent state | |
| Observations | Noisy linear readout of |
The joint distribution is:
Each factor is defined as follows.
Discrete chain (HMM). The discrete states follow a Markov chain with initial distribution and transition matrix :
Continuous chain (switched LDS). Given the discrete state, the continuous state evolves as a linear Gaussian with regime-specific parameters:
Emissions (shared). Observations are a noisy linear readout of the continuous state, shared across all regimes:
The parameters are .
Exact Inference is Intractable¶
For EM, the E-step requires computing the posterior . The natural approach is to run a forward pass over the hybrid state , maintaining the joint message
At this is a mixture of Gaussians (one per initial discrete state). Propagating one step, for each :
Each of the existing Gaussian components at time spawns new components at time (one for each incoming discrete state). The number of components multiplies at each step:
For and , this is — clearly intractable. We need an approximation.
Approximate Message Passing: Gaussian Sum Filter¶
Rather than abandoning message passing altogether, one family of approximations attempts to keep the forward pass tractable by maintaining a bounded-size mixture at each step. The idea is simple: the exact forward message after steps is a mixture of Gaussians; instead, we maintain only Gaussian components per discrete state (for some small fixed ), and after each propagation step we collapse the expanded mixture back to components. This is the Gaussian Sum Filter (GSF) Barber, 2012, Ch.~25.
The Gaussian Sum Filter¶
Represent the filtered distribution as a finite mixture, separately for each discrete state :
where for each . The full filtered distribution is a mixture of Gaussians in total.
Propagation. Given the -component approximation at time , one forward step produces a component mixture at time : for each incoming component and each new discrete state , run a standard Kalman predict-update step with dynamics and observation :
The weight of this component is proportional to:
where is the Gaussian predictive likelihood from the Kalman step.
Collapse. To keep the mixture bounded at components per discrete state, merge the components for each back to . The simplest approach retains the highest-weight components and merges the remaining ones into a single Gaussian by moment matching: given components with weights and parameters , compute
This completes one forward step of the Gaussian Sum Filter.
The Special Case¶
With (a single Gaussian per discrete state), the filter collapses to the single-component approximation, sometimes called the Gaussian Sum Filter with moment matching or, in the engineering literature, the Interacting Multiple Models (IMM) filter. At each step the continuous distribution conditioned on each discrete state is approximated by a single Gaussian:
The marginal over the continuous state is then a -component mixture:
This is tractable at every step: total, since each of the Kalman steps costs and there are component pairs.
Approximate Smoothing¶
The backward (smoothing) pass requires analogous approximations. One popular method is the Expectation Correction (EC) smoother Barber, 2012, which approximates , dropping the dependence on the current discrete state. This allows an RTS-style backward recursion for each discrete state, followed by moment-matching to collapse the resulting mixture.
A simpler alternative is Generalised Pseudo-Bayes (GPB) smoothing, which approximates and runs the HMM backward pass independently of the continuous backward recursion. GPB is computationally cheaper but discards future information passed through the continuous variables.
Structured Mean-Field Variational Inference¶
The Mean-Field Family¶
The structured mean-field approximation breaks the dependence between the two chains while preserving the Markov structure within each:
We require that factorises as an HMM-type chain and factorises as an LDS-type chain. We find the best by minimising the KL divergence:
By the CAVI theorem (CAVI chapter), the optimal update for each factor, holding the other fixed, is:
CAVI Update for ¶
Collecting terms that involve :
where the expected log-likelihoods under are:
This has exactly the structure of an HMM with log-likelihoods in place of observation log-likelihoods.
update: run HMM forward-backward with transition matrix and log-likelihoods to obtain the marginals and pairwise marginals .
Computing . Expanding the Gaussian log-likelihood, the expectation requires only three smoother moments: , , and . All three are available from the RTS smoother run in the previous update.
CAVI Update for ¶
Collecting terms that involve :
The emission terms do not depend on . The dynamics terms average over using the marginals :
With a shared noise covariance (same for all ), this sum of log-Gaussians is itself a log-Gaussian with effective dynamics:
update: run Kalman filter + RTS smoother with time-varying dynamics and fixed emissions to obtain the smoothed moments , , .
Full Variational EM Algorithm¶
Combining the two CAVI updates with an M-step gives the full algorithm.
Initialize: for all .
Repeat until convergence:
(E.1) Compute expected log-likelihoods: for each and ,
(E.2) Update : run HMM forward-backward with to obtain and .
(E.3) Update : run Kalman filter + RTS smoother with soft-averaged dynamics and to obtain , , .
(M-step) Update parameters using the expected sufficient statistics:
Recurrent SLDS¶
Motivation and Model¶
In the standard SLDS, the transition depends only on the previous discrete state — the continuous state has no influence on which regime is active next. This is a significant limitation: in many physical systems, regime changes are triggered by crossing a threshold in the continuous state (e.g. a neuron switching firing mode when membrane potential crosses a threshold; a locomotor system changing gait when speed exceeds a threshold).
The Recurrent SLDS (rSLDS) Linderman et al., 2017 adds a direct dependence of the discrete transition on the previous continuous state :
The weight vectors define hyperplanes that partition the continuous state space: the model transitions to regime when lies in the region where is largest. This couples the two chains far more tightly: the discrete state depends on the continuous state, and the continuous dynamics depend on the discrete state.
The rSLDS has been applied to neural population dynamics, where the continuous state represents a latent neural trajectory and the discrete state represents distinct decision-making phases Zoltowski et al., 2020. The recurrent transitions allow the model to learn where in latent space each phase applies, rather than treating phase transitions as random.
Challenge for inference. The expected log-likelihoods for the update now include a softmax log-probability that is nonlinear in :
The nonlinear softmax term means the update is no longer a standard Kalman pass. This motivates the Variational Laplace EM algorithm described next.
Variational Laplace EM¶
Key idea Zoltowski et al., 2020. Rather than trying to compute in closed form, approximate it with a Laplace approximation around the MAP estimate:
where
Block-tridiagonal structure. The Markov structure of the model means is coupled to and in the log-posterior but not to more distant time steps. Consequently is block-tridiagonal with blocks of size . The MAP solve (Newton’s method) and the Hessian inversion both cost — the same as a Kalman smoother pass.
Reduction to Kalman smoother. For the standard SLDS with linear Gaussian dynamics and a fixed discrete sequence, the log-posterior is quadratic in , so the Laplace approximation is exact: is the RTS smoother mean and is the RTS smoother covariance.
Algorithm. The variational Laplace EM algorithm Zoltowski et al., 2020 alternates the same three steps as structured mean-field, but replaces the Kalman smoother in E.3 with a MAP solve:
(E.1) Find MAP by Newton’s method on ; compute block-tridiagonal from the Hessian at .
(E.2) Compute using moments from and (including the nonlinear softmax log-probability).
(E.3) Update : run HMM forward-backward with .
Implementation: Structured Mean-Field VI¶
We implement the structured mean-field algorithm for an SLDS with shared emission parameters and shared noise covariance .
Helper: Kalman Filter and RTS Smoother¶
We need a Kalman filter that accepts time-varying dynamics (the soft-averaged matrices from ), and an RTS smoother that also returns the lagged cross-covariances needed to evaluate .
def kalman_filter_tvd(y, A_seq, b_seq, Q, C, d, R, mu0, Sigma0):
"""Kalman filter with time-varying dynamics.
Args:
y: (T, Dy)
A_seq: (T, Dx, Dx) time-varying dynamics; A_seq[t] used for step t->t+1
b_seq: (T, Dx)
Q: (Dx, Dx) shared dynamics noise covariance
C: (Dy, Dx)
d: (Dy,)
R: (Dy, Dy)
mu0: (Dx,)
Sigma0: (Dx, Dx)
Returns:
μ_filt (T, Dx), Σ_filt (T, Dx, Dx)
μ_pred (T, Dx), Σ_pred (T, Dx, Dx)
G_gains (T-1, Dx, Dx) smoother gains (computed here for reuse)
log_ml scalar
"""
T, Dy = y.shape
Dx = mu0.shape[0]
I = torch.eye(Dx)
μ_filt = torch.zeros(T, Dx)
Σ_filt = torch.zeros(T, Dx, Dx)
μ_pred = torch.zeros(T, Dx)
Σ_pred = torch.zeros(T, Dx, Dx)
log_ml = 0.0
μ = mu0.clone()
Σ = Sigma0.clone()
for t in range(T):
μ_pred[t] = μ
Σ_pred[t] = Σ
# Update
innov = y[t] - C @ μ - d
S = C @ Σ @ C.T + R
K = Σ @ C.T @ torch.linalg.solve(S, torch.eye(Dy))
μ = μ + K @ innov
Σ = (I - K @ C) @ Σ
log_ml += dist.MultivariateNormal(C @ μ_pred[t] + d, S).log_prob(y[t])
μ_filt[t] = μ
Σ_filt[t] = Σ
# Predict (not needed after last step)
if t < T - 1:
A_t = A_seq[t]
μ = A_t @ μ + b_seq[t]
Σ = A_t @ Σ @ A_t.T + Q
return μ_filt, Σ_filt, μ_pred, Σ_pred, log_ml
def rts_smoother_tvd(A_seq, μ_filt, Σ_filt, μ_pred, Σ_pred):
"""RTS smoother with time-varying dynamics.
Returns smoothed means, covariances, smoother gains, and lagged
cross-covariances Cov[x_t, x_{t-1} | y_{1:T}] = Σ_{t|T} G_{t-1}^T.
"""
T, Dx = μ_filt.shape
μ_smooth = μ_filt.clone()
Σ_smooth = Σ_filt.clone()
G_gains = torch.zeros(T - 1, Dx, Dx)
cross_covs = torch.zeros(T - 1, Dx, Dx) # Cov[x_t, x_{t-1}], indexed by t
for t in range(T - 2, -1, -1):
A_t = A_seq[t]
G = Σ_filt[t] @ A_t.T @ torch.linalg.solve(Σ_pred[t + 1], torch.eye(Dx))
G_gains[t] = G
μ_smooth[t] = μ_filt[t] + G @ (μ_smooth[t + 1] - μ_pred[t + 1])
Σ_smooth[t] = Σ_filt[t] + G @ (Σ_smooth[t + 1] - Σ_pred[t + 1]) @ G.T
# Cov[x_{t+1}, x_t | y_{1:T}] = Σ_{t+1|T} G_t^T
cross_covs[t] = Σ_smooth[t + 1] @ G.T
return μ_smooth, Σ_smooth, G_gains, cross_covs# ── Expected log-likelihoods ℓ_t(k) ──────────────────────────────────────────
def compute_ell(μ_s, Σ_s, cross_covs, A_list, b_list, Q):
"""Compute ℓ_t(k) = E_{q(x)}[log p(x_t | x_{t-1}, z_t=k)] for t=1,...,T-1.
Args:
μ_s: (T, Dx) smoothed means
Σ_s: (T, Dx, Dx) smoothed covariances
cross_covs: (T-1, Dx, Dx) cross_covs[t] = Cov[x_{t+1}, x_t | y_{1:T}]
A_list: list of K (Dx, Dx) dynamics matrices
b_list: list of K (Dx,) biases
Q: (Dx, Dx)
Returns:
ell: (T-1, K) log-likelihoods for t=1,...,T-1
(t=0 not included since x_t|x_{t-1} only defined for t>=1)
"""
T, Dx = μ_s.shape
K = len(A_list)
Q_inv = torch.linalg.inv(Q)
log_det_Q = torch.logdet(Q)
const = -0.5 * (Dx * torch.log(torch.tensor(2 * torch.pi)) + log_det_Q)
# Second moments
E_xt_xt = Σ_s[1:] + μ_s[1:].unsqueeze(2) * μ_s[1:].unsqueeze(1) # (T-1,Dx,Dx)
E_xp_xp = Σ_s[:-1] + μ_s[:-1].unsqueeze(2) * μ_s[:-1].unsqueeze(1) # (T-1,Dx,Dx)
# cross_covs[t] = Cov[x_{t+1},x_t] so E[x_{t+1} x_t^T] = cross_covs[t] + mu[t+1] mu[t]^T
E_xt_xp = cross_covs + μ_s[1:].unsqueeze(2) * μ_s[:-1].unsqueeze(1) # (T-1,Dx,Dx)
ell = torch.zeros(T - 1, K)
for k, (A_k, b_k) in enumerate(zip(A_list, b_list)):
# E[||Q^{-1/2}(x_t - A_k x_{t-1} - b_k)||^2]
# = Tr[Q_inv @ (E[x_t x_t^T] - E[x_t x_{t-1}^T] A_k^T - b_k E[x_t]^T
# - A_k E[x_{t-1} x_t^T] + A_k E[x_{t-1} x_{t-1}^T] A_k^T
# + A_k E[x_{t-1}] b_k^T - b_k E[x_{t-1}]^T A_k^T + b_k b_k^T)]
# Combine into M_t for each t:
M = (E_xt_xt
- E_xt_xp @ A_k.T # -E[x_t x_{t-1}^T] A_k^T
- μ_s[1:].unsqueeze(2) * b_k.unsqueeze(0).unsqueeze(0) # -b_k E[x_t]^T (outer)
- A_k @ E_xt_xp.transpose(1, 2) # -A_k E[x_{t-1} x_t^T]
+ A_k @ E_xp_xp @ A_k.T # A_k E[x_{t-1}^2] A_k^T
+ (A_k @ μ_s[:-1].unsqueeze(2)) * b_k.unsqueeze(0).unsqueeze(0) # A_k mu b_k^T
- b_k.unsqueeze(1) * (A_k @ μ_s[:-1].unsqueeze(2)).squeeze(2).unsqueeze(1) # b_k mu^T A_k^T
+ b_k.unsqueeze(1) * b_k.unsqueeze(0)) # b_k b_k^T
ell[:, k] = const - 0.5 * torch.einsum('tij,ji->t', M, Q_inv)
return ell # (T-1, K)
# ── HMM forward-backward (reusing the convention from ch. 04_01) ──────────────
def hmm_forward(log_pi0, log_P, log_ell):
"""Normalized forward messages. Returns log_alphas (T, K) and log_norms (T,).
Convention: log_alphas[t, k] = log p(z_t=k | y_{1:t-1}) (predictive).
log_ell[t, k] = log p(x_t | x_{t-1}, z_t=k) (ell_t(k) from compute_ell,
extended with a zero column at t=0 since z_1 has no dynamics likelihood).
"""
T, K = log_ell.shape
log_alphas = torch.zeros(T, K)
log_norms = torch.zeros(T)
log_alphas[0] = log_pi0 - torch.logsumexp(log_pi0, 0)
log_norms[0] = torch.logsumexp(log_alphas[0] + log_ell[0], 0)
for t in range(1, T):
log_joint = log_alphas[t - 1] + log_ell[t - 1]
log_alpha_t = torch.logsumexp(log_joint[:, None] + log_P, 0)
log_alphas[t] = log_alpha_t - torch.logsumexp(log_alpha_t, 0)
log_norms[t] = torch.logsumexp(log_alphas[t] + log_ell[t], 0)
return log_alphas, log_norms
def hmm_backward(log_P, log_ell):
T, K = log_ell.shape
log_betas = torch.zeros(T, K)
for t in range(T - 2, -1, -1):
log_joint = log_ell[t + 1] + log_betas[t + 1]
log_beta_t = torch.logsumexp(log_P + log_joint[None, :], 1)
log_betas[t] = log_beta_t - torch.logsumexp(log_beta_t, 0)
return log_betas
def hmm_marginals(log_alphas, log_betas, log_ell):
log_gamma = log_alphas + log_ell + log_betas
log_gamma -= torch.logsumexp(log_gamma, 1, keepdim=True)
return log_gamma.exp() # (T, K)
def hmm_pair_marginals(log_alphas, log_betas, log_ell, log_P):
T, K = log_alphas.shape
log_xi = (log_alphas[:-1, :, None]
+ log_ell[:-1, :, None]
+ log_P[None]
+ log_ell[1:, None, :]
+ log_betas[1:, None, :])
log_xi -= torch.logsumexp(log_xi.reshape(T - 1, -1), 1).reshape(T - 1, 1, 1)
return log_xi.exp() # (T-1, K, K)# ── Structured mean-field variational EM ─────────────────────────────────────
def slds_mean_field_em(
y,
A_list, b_list, Q,
C, d, R,
pi0, P,
mu0, Sigma0,
num_iters=30,
):
"""Structured mean-field variational EM for SLDS.
Parameters are assumed fixed (E-step only; M-step not implemented here).
Args:
y: (T, Dy)
A_list: list of K (Dx, Dx)
b_list: list of K (Dx,)
Q: (Dx, Dx) shared dynamics noise
C: (Dy, Dx)
d: (Dy,)
R: (Dy, Dy)
pi0: (K,) initial discrete distribution
P: (K, K) transition matrix
mu0: (Dx,) initial continuous mean
Sigma0: (Dx, Dx)
Returns:
γ: (T, K) posterior marginals q(z_t=k)
μ_s: (T, Dx) smoothed continuous means
Σ_s: (T, Dx, Dx) smoothed continuous covariances
"""
T, Dy = y.shape
K = len(A_list)
Dx = A_list[0].shape[0]
A_stack = torch.stack(A_list) # (K, Dx, Dx)
b_stack = torch.stack(b_list) # (K, Dx)
log_P = P.log()
log_pi0 = pi0.log()
# Initialize γ uniformly
γ = torch.full((T, K), 1.0 / K)
μ_s = torch.zeros(T, Dx)
Σ_s = torch.zeros(T, Dx, Dx)
cross_covs = torch.zeros(T - 1, Dx, Dx)
for _ in range(num_iters):
# ── E.3: update q(x) with soft-averaged dynamics ──────────────────
A_eff = torch.einsum('tk,kij->tij', γ, A_stack) # (T, Dx, Dx)
b_eff = torch.einsum('tk,ki->ti', γ, b_stack) # (T, Dx)
μ_filt, Σ_filt, μ_pred, Σ_pred, _ = kalman_filter_tvd(
y, A_eff, b_eff, Q, C, d, R, mu0, Sigma0)
μ_s, Σ_s, _, cross_covs = rts_smoother_tvd(
A_eff, μ_filt, Σ_filt, μ_pred, Σ_pred)
# ── E.1: compute ℓ_t(k) ──────────────────────────────────────────
ell = compute_ell(μ_s, Σ_s, cross_covs, A_list, b_list, Q) # (T-1, K)
# Pad to (T, K): t=0 has no dynamics likelihood so set to 0
log_ell = torch.cat([torch.zeros(1, K), ell], dim=0) # (T, K)
# ── E.2: update q(z) via HMM forward-backward ────────────────────
log_alphas, _ = hmm_forward(log_pi0, log_P, log_ell)
log_betas = hmm_backward(log_P, log_ell)
γ = hmm_marginals(log_alphas, log_betas, log_ell)
return γ, μ_s, Σ_s# ── Simulate from a two-regime SLDS ──────────────────────────────────────────
# Regime 1: slow clockwise rotation (stable spiral in)
# Regime 2: fast counter-clockwise rotation (stable spiral out, then in)
torch.manual_seed(305)
K, Dx, Dy = 2, 2, 2
T = 150
# Regime 1: slowly decaying clockwise rotation
θ1 = torch.tensor(0.15) # rotation angle
r1 = 0.97
A1 = r1 * torch.tensor([[torch.cos(θ1), -torch.sin(θ1)],
[torch.sin(θ1), torch.cos(θ1)]])
b1 = torch.zeros(Dx)
# Regime 2: faster counter-clockwise rotation with slight expansion
θ2 = torch.tensor(-0.35)
r2 = 0.94
A2 = r2 * torch.tensor([[torch.cos(θ2), -torch.sin(θ2)],
[torch.sin(θ2), torch.cos(θ2)]])
b2 = torch.zeros(Dx)
Q = 0.03 * torch.eye(Dx)
C = torch.eye(Dy, Dx)
d = torch.zeros(Dy)
R = 0.2 * torch.eye(Dy)
pi0 = torch.tensor([0.8, 0.2])
P = torch.tensor([[0.95, 0.05],
[0.10, 0.90]])
mu0 = torch.tensor([2.0, 0.0])
Sigma0 = 0.1 * torch.eye(Dx)
# Simulate
z_true = torch.zeros(T, dtype=torch.long)
x_true = torch.zeros(T, Dx)
y_obs = torch.zeros(T, Dy)
z_true[0] = dist.Categorical(pi0).sample()
x_true[0] = dist.MultivariateNormal(mu0, Sigma0).sample()
y_obs[0] = dist.MultivariateNormal(C @ x_true[0] + d, R).sample()
A_list = [A1, A2]
b_list = [b1, b2]
A_stack = torch.stack(A_list)
b_stack = torch.stack(b_list)
for t in range(1, T):
z_true[t] = dist.Categorical(P[z_true[t - 1]]).sample()
A_t = A_list[z_true[t].item()]
b_t = b_list[z_true[t].item()]
x_true[t] = dist.MultivariateNormal(A_t @ x_true[t - 1] + b_t, Q).sample()
y_obs[t] = dist.MultivariateNormal(C @ x_true[t] + d, R).sample()
print(f'Regime 1 fraction: {(z_true == 0).float().mean():.2f}')
print(f'Regime 2 fraction: {(z_true == 1).float().mean():.2f}')Regime 1 fraction: 0.67
Regime 2 fraction: 0.33
# ── Run structured mean-field VI ──────────────────────────────────────────────
γ, μ_smooth, Σ_smooth = slds_mean_field_em(
y_obs, A_list, b_list, Q, C, d, R, pi0, P, mu0, Sigma0, num_iters=40)
# Align labels: regime with higher γ when z_true=0 should be z_inferred=0
mean_γ0 = γ[z_true == 0, 0].mean()
if mean_γ0 < 0.5:
γ = γ.flip(1) # swap inferred labels
print(f'Mean posterior p(z_t=0): {γ[:, 0].mean():.3f} (true fraction: {(z_true==0).float().mean():.3f})')Mean posterior p(z_t=0): 0.644 (true fraction: 0.667)
# ── Visualisation ─────────────────────────────────────────────────────────────
fig, axes = plt.subplots(2, 2, figsize=(13, 10))
t_vals = np.arange(T)
c0, c1 = palette[0], palette[1]
# ── Panel 1: 2D latent trajectories coloured by true regime ──────────────────
ax = axes[0, 0]
for t in range(T - 1):
col = c0 if z_true[t] == 0 else c1
ax.plot(x_true[t:t+2, 0].numpy(), x_true[t:t+2, 1].numpy(),
color=col, lw=1.2, alpha=0.8)
ax.scatter(y_obs[:, 0].numpy(), y_obs[:, 1].numpy(),
s=8, c='gray', alpha=0.4, zorder=1, label='Observations')
ax.plot(μ_smooth[:, 0].numpy(), μ_smooth[:, 1].numpy(),
'k--', lw=1.0, alpha=0.7, label=r'Smoothed $\hat{\mathbf{x}}_t$')
p0 = mpatches.Patch(color=c0, label='Regime 1 (true)')
p1 = mpatches.Patch(color=c1, label='Regime 2 (true)')
ax.legend(handles=[p0, p1] + ax.get_legend_handles_labels()[0][-1:],
fontsize=8, loc='upper right')
ax.set_title('Latent trajectory: true regimes')
ax.set_xlabel(r'$x_1$')
ax.set_ylabel(r'$x_2$')
ax.set_aspect('equal')
# ── Panel 2: discrete state — true vs inferred ────────────────────────────────
ax = axes[0, 1]
ax.step(t_vals, z_true.numpy(), where='post', color='k', lw=1.2, label='True $z_t$')
ax.fill_between(t_vals, 0, γ[:, 1].numpy(), alpha=0.5, color=c1,
step='post', label='$q(z_t=2)$')
ax.set_yticks([0, 1])
ax.set_yticklabels(['Regime 1', 'Regime 2'])
ax.set_xlabel('Time $t$')
ax.set_title('Discrete state: true (step) and inferred (shaded)')
ax.legend(fontsize=9)
# ── Panel 3: smoothed x_1 coordinate with uncertainty ────────────────────────
ax = axes[1, 0]
σ_x1 = Σ_smooth[:, 0, 0].sqrt().numpy()
ax.plot(t_vals, x_true[:, 0].numpy(), 'k-', lw=1.2, label='True $x_1$')
ax.scatter(t_vals, y_obs[:, 0].numpy(), s=8, alpha=0.4, color='gray', label='Observed')
ax.plot(t_vals, μ_smooth[:, 0].numpy(), color=palette[2], lw=1.5,
label=r'$\hat{x}_{1,t}$ (smoothed)')
ax.fill_between(t_vals,
μ_smooth[:, 0].numpy() - 2 * σ_x1,
μ_smooth[:, 0].numpy() + 2 * σ_x1,
alpha=0.25, color=palette[2], label=r'$\pm 2\sigma$')
ax.set_xlabel('Time $t$')
ax.set_ylabel(r'$x_1$')
ax.set_title(r'Smoothed continuous state $x_1$')
ax.legend(fontsize=9)
# ── Panel 4: per-regime soft assignments over time ────────────────────────────
ax = axes[1, 1]
ax.stackplot(t_vals, γ[:, 0].numpy(), γ[:, 1].numpy(),
colors=[c0, c1], alpha=0.7,
labels=['$q(z_t=1)$', '$q(z_t=2)$'])
ax.set_ylim(0, 1)
ax.set_xlabel('Time $t$')
ax.set_ylabel('Posterior probability')
ax.set_title('Soft regime assignments $\\gamma_t(k)$')
ax.legend(fontsize=9, loc='upper right')
plt.tight_layout()
plt.show()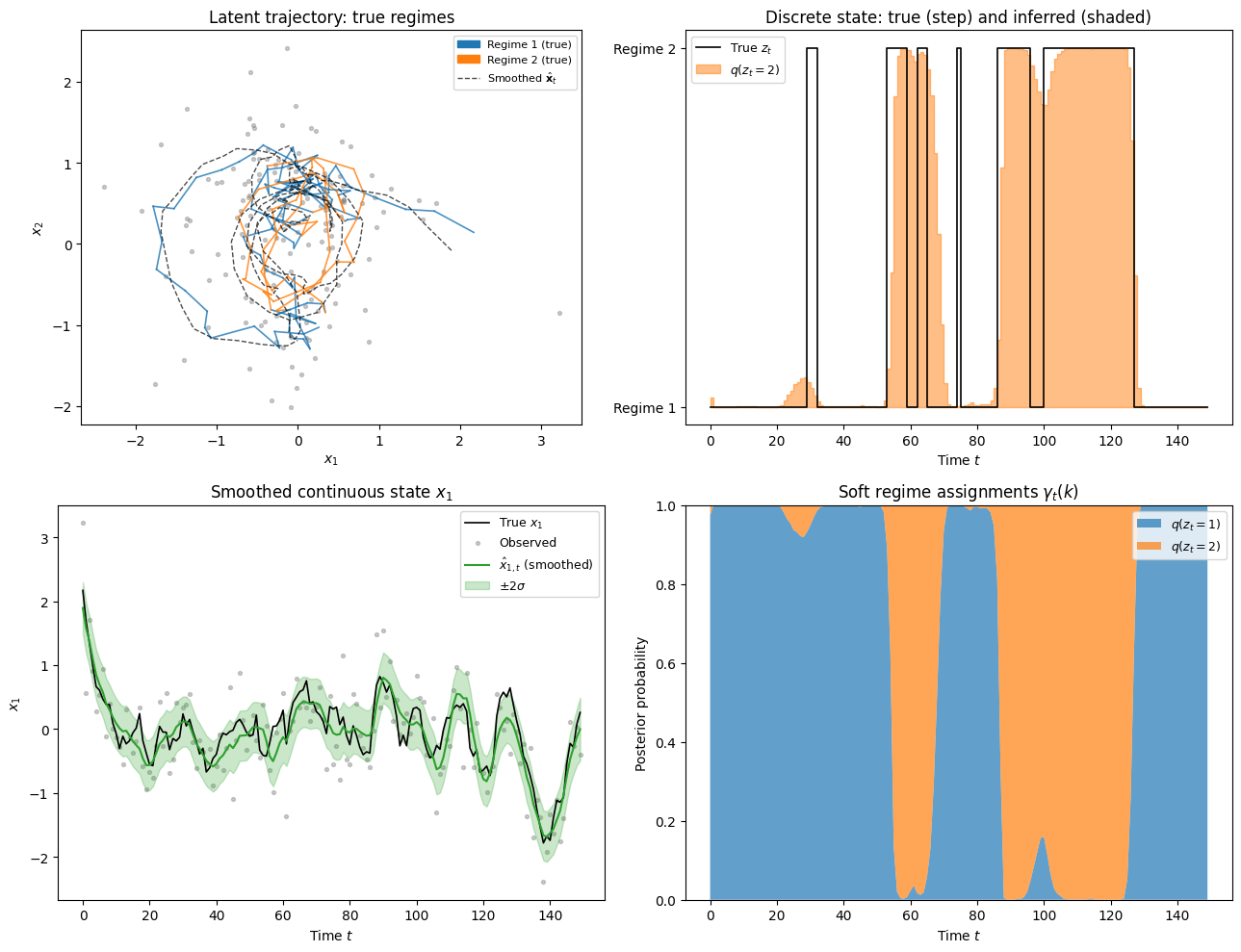
Conclusion¶
The SLDS extends both HMMs and LDS by combining a discrete regime variable with a continuous latent state, enabling models that switch sharply between linear dynamical regimes. The table below places it in context alongside its relatives.
| Model | Latent state | Inference algorithm |
|---|---|---|
| HMM | discrete | Forward-backward |
| LDS | continuous | Kalman filter + RTS smoother |
| SLDS | discrete continuous | See below |
| rSLDS | discrete continuous, recurrent transitions | See below |
The SLDS and rSLDS are hybrid models whose exact posterior is intractable. The table below summarises the main approximation strategies, differing in whether they target the filtered or smoothed posterior and how they represent the continuous state.
| Approach | Setting | Handles rSLDS? | Cost per step | |
|---|---|---|---|---|
| Exact (intractable) | Online/offline | Gaussians at step | — | |
| Gaussian Sum Filter ( comp.) | Online | Gaussians per state | No | |
| Single-component GSF () | Online | 1 Gaussian per state | No | |
| Structured mean-field VI | Offline | LDS-chain smoother | Approximately | |
| Variational Laplace EM | Offline | MAP + block-tridiag Hessian | Yes | per Newton step |
- Barber, D. (2012). Bayesian Reasoning and Machine Learning. Cambridge University Press.
- Linderman, S., Johnson, M., Miller, A., Adams, R., Blei, D., & Paninski, L. (2017). Bayesian Learning and Inference in Recurrent Switching Linear Dynamical Systems. Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, 914–922.
- Zoltowski, D., Pillow, J., & Linderman, S. (2020). A General Recurrent State Space Framework for Modeling Neural Dynamics during Decision-Making. Proceedings of the 37th International Conference on Machine Learning, 11680–11691.
- Ghahramani, Z., & Hinton, G. E. (1996). Switching State-Space Models. Technical Report CRG-TR-96-3, University of Toronto.