The multivariate normal (MVN) distribution — also called the multivariate Gaussian — is the workhorse of probabilistic machine learning. It is one of the few distributions in more than one dimension that we can work with analytically, and it arises naturally as the limiting distribution of sums of independent random vectors (the multivariate central limit theorem). Many of the models we study in this course are built from MVN distributions as building blocks.
In this lecture we cover:
The MVN distribution: generative story, density, marginals, conditionals, linear Gaussian models
Maximum likelihood estimation
The Wishart and inverse Wishart distributions
Bayesian estimation with a normal-inverse-Wishart (NIW) prior
Posterior marginals: the multivariate Student’s t distribution
Source
import torch
from torch.distributions import Normal, MultivariateNormal, Wishart
import matplotlib.pyplot as plt
def plot_cov(Σ, μ=None, ax=None, **kwargs):
"""Visualize a 2D covariance matrix as a 1-σ ellipse."""
D = Σ.shape[-1]
μ = torch.zeros(D) if μ is None else μ
λ_diag, U = torch.linalg.eigh(Σ)
zs = torch.column_stack([
torch.cos(torch.linspace(0, 2 * torch.pi, 50)),
torch.sin(torch.linspace(0, 2 * torch.pi, 50))
])
xs = (zs * torch.sqrt(λ_diag)) @ U.T
ax = plt.axes(aspect=1) if ax is None else ax
ax.plot(μ[0] + xs[:, 0], μ[1] + xs[:, 1], **kwargs)
The cleanest way to understand the MVN is to build it up from scratch. Start with a vector of standard normal random variates, z=[z1,…,zD]⊤, where each component is drawn independently,
This D-dimensional random variable is the simplest possible multivariate Gaussian, but it is not very interesting — all the coordinates are independent and have unit variance. Its joint density factors as a product of univariate Gaussians,
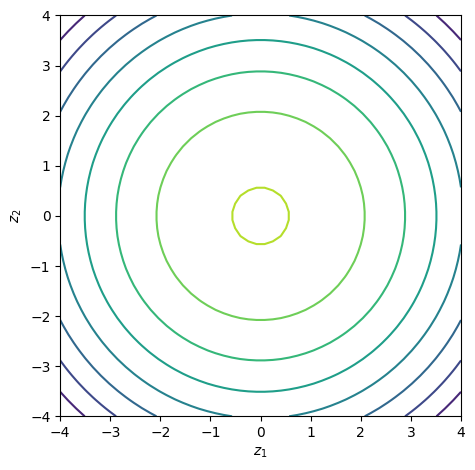
The last step recognizes this as a multivariate normal with zero mean and identity covariance. In D=2 dimensions, the contours of constant density are circles centered at the origin — hence the name spherical Gaussian.
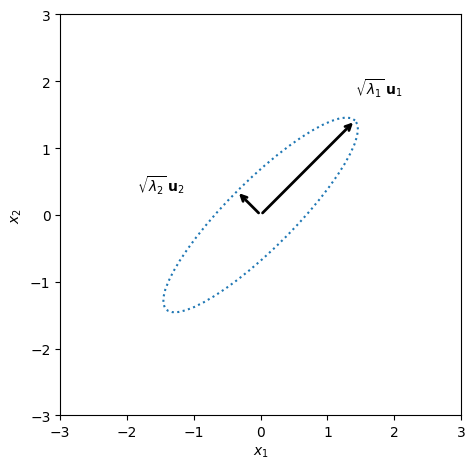
We can obtain more interesting joint distributions by linearly transforming this random vector. Let U be an orthogonal D×D matrix (so U⊤U=I) whose columns are the eigenvectors of a desired covariance, and let Λ=diag([λ1,…,λD]) with λd>0 be a diagonal matrix of eigenvalues. Define,
The matrix U rotates the coordinate axes, while Λ1/2 stretches each axis by a factor of λd. The result is a random vector whose variance along the d-th eigenvector is λd.
To find the density of x=UΛ1/2z, we apply the multivariate change-of-variables formula. Since x is an invertible linear function of z, with z=Λ−1/2U⊤x, the density transforms as,
where Σ=UΛU⊤. The key steps are: (i) the Jacobian of the linear map is the absolute value of the determinant of Λ−1/2U⊤; (ii) since U is orthogonal, ∣U⊤∣=1; and (iii) ∣Λ−1/2∣=∣Λ∣−1/2 since Λ is diagonal.
Adding a translation so that x=UΛ21z+μ for μ∈RD, the same argument gives the general MVN density,
This is a generalization of the squared Euclidean distance that accounts for the scale and orientation of the distribution. Points x at equal Mahalanobis distance from μ lie on an ellipse whose axes are aligned with the eigenvectors of Σ and whose radii are proportional to λd.
The construction above used a specific structure for the transformation matrix — an orthogonal matrix times a diagonal scaling. But we could apply any linear transformation to the standard normal,
This is sometimes called the square root form of the MVN — A is a square root of the covariance matrix. When M>D, the covariance Σ=AA⊤ has rank at most D<M, so it is only positive semidefinite. This yields a degenerate multivariate normal whose density does not exist with respect to Lebesgue measure on RM; instead, the distribution is supported on a D-dimensional subspace.
To sample x∼N(μ,Σ) in practice, we need to find a square root Σ21∈RD×D such that Σ=(Σ21)(Σ21)⊤, then draw z∼N(0,I) and set x=Σ21z+μ. Common choices include:
Eigendecomposition:Σ21=UΛ21 where Σ=UΛU⊤. This is geometrically natural but more expensive to compute.
Cholesky decomposition:Σ21=chol(Σ), the unique lower-triangular square root. This is numerically efficient and is the standard choice in practice.
This follows immediately from the generative story: Ax+b=A(Σ1/2z+μ)+b=(AΣ1/2)z+(Aμ+b), which is an affine function of the standard normal z. The mean transforms linearly and the covariance transforms by a congruence. This property means, for instance, that projecting a multivariate normal onto any subspace gives a (lower-dimensional) multivariate normal.
Suppose we have a joint MVN on a vector x∈RD and we want to integrate out some of the variables. Partition x and the MVN parameters into two subsets a and b,
The block Σaa is the covariance of xa with itself, Σbb is the covariance of xb with itself, and Σab=Σba⊤ captures the cross-covariances between the two subsets.
Marginalizing over xb is equivalent to applying the linear transformation A=[I0] (an identity block followed by zeros) so that Ax=xa. By the closure under linear transformations,
This is a remarkably simple result: to obtain the marginal of a subset of variables, just extract the corresponding blocks of the mean vector and covariance matrix. There is no integration needed — the marginal is determined directly by the parameters of the joint distribution.
Conditioning is more involved than marginalization, but the MVN remains tractable. We want to find p(xa∣xb). It helps to work with the precision matrix (the inverse of the covariance), Σ−1≜Λ, written in the same block form,
The quantity Σaa−ΣabΣbb−1Σba is the Schur complement of Σbb in Σ. It will appear again as the conditional covariance.
To find the conditional distribution, we treat xb as fixed and expand the joint log density as a function of xa alone. Using Bayes’ rule and the block precision matrix,
where we collected terms quadratic and linear in xa, defining the information matrixJa∣b=Λaa and information vectorha∣b=Λaaμa−Λab(xb−μb). The exponent is a quadratic in xa, which means the conditional is also Gaussian — this is the information form of the conditional density.
Completing the square (as in Lecture 1), we convert from information form back to the standard mean-covariance form and find,
Two properties of these formulas are worth noting. First, the conditional covariance Σa∣b does not depend on the observed value xb — conditioning on xb reduces our uncertainty about xa by a fixed amount regardless of what xb turns out to be. Second, the conditional mean μa∣b is a linear function of xb: it starts at the marginal mean μa and shifts by an amount proportional to how much xb deviates from its own marginal mean μb. The matrix ΣabΣbb−1 is the multivariate analog of the regression coefficient in simple linear regression.
Here x∈RDx is a latent (unobserved) variable with prior mean b and covariance Q, and y∈RDy is an observation generated by applying a linear map C to x, adding a bias d, and corrupting with Gaussian noise of covariance R. This model appears throughout this course: as a factor analysis model (when Dx<Dy), as the observation model in a Kalman filter, and as a building block for Gaussian process regression.
The key question is: what is the joint distribution p(x,y)? We can answer this by writing x and y as explicit linear functions of independent standard normals. Let zx∼N(0,IDx) and zy∼N(0,IDy) be independent. Then,
Reading off the blocks, we see that the marginal distribution of y is N(Cb+d,CQC⊤+R). The cross-covariance QC⊤ reflects the fact that x and y share the common noise term Q1/2zx. Given the joint distribution, we can also compute the conditional distribution p(x∣y) using the formulas from the previous section — this is the core of Bayesian linear regression and the Kalman filter.
The MLE for the mean is the sample mean, and the MLE for the covariance is the sample covariance (with a factor of 1/N rather than 1/(N−1), so it is slightly biased downward for finite N). Both are intuitive and easy to compute.
The hyperparameters η=(μ0,Σ0,Σ) encode our prior beliefs: μ0 is our prior guess for the mean, and Σ0 captures how uncertain we are about that guess (Σ0−1 is the prior precision). Our goal is to compute the posterior p(μ∣X,η).
By Bayes’ rule, the posterior is proportional to the prior times the likelihood. Expanding the exponents and collecting terms quadratic and linear in μ,
where we have defined the posterior precision matrixJN=Σ0−1+NΣ−1 and posterior information vectorhN=Σ0−1μ0+∑n=1NΣ−1xn. This has the form of a Gaussian in information parametrization (quadratic in μ), so completing the square gives a Gaussian posterior,
with xˉ=N1∑n=1Nxn denoting the sample mean. The posterior precision is the sum of the prior precision and the data precision — information about the mean accumulates additively. The posterior mean is a precision-weighted average of the prior mean and the sample mean.
In the uninformative limit Σ0−1→0 (infinite prior uncertainty), the posterior mean converges to the sample mean xˉ and the posterior covariance converges to N1Σ — the distribution you would get from a Gaussian centered on the MLE.
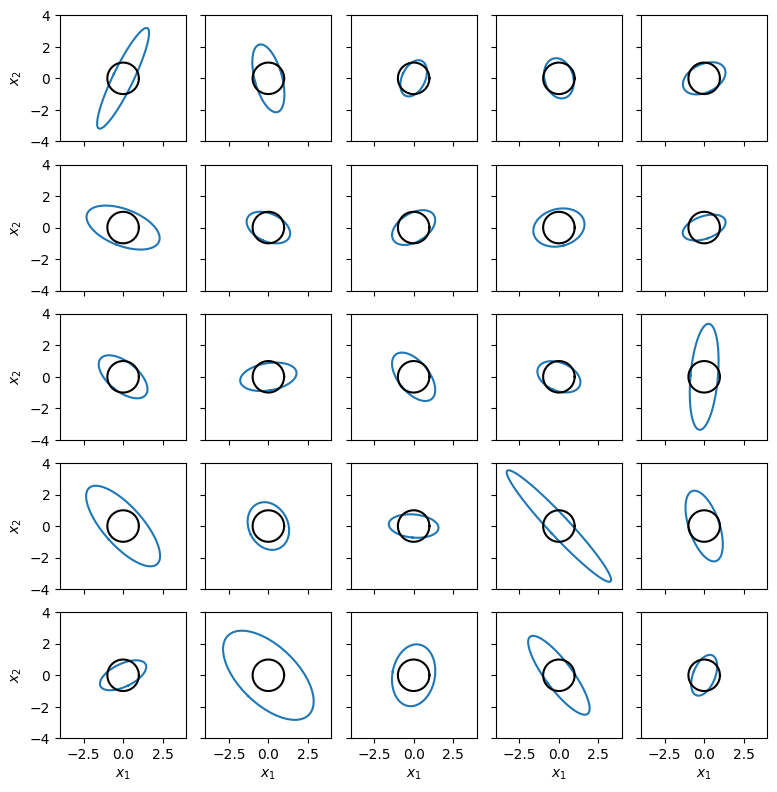
Now suppose the mean μ is known but the covariance (or equivalently, the precision) is unknown. To build intuition for the prior, recall how we handled the univariate case in Lecture 1: the χ2 distribution arose as the distribution of the sum of squared standard normal random variables. The Wishart distribution is the natural multivariate generalization of this construction.
Let z1,…,zν0 be i.i.d. draws from a zero-mean multivariate normal,
The sum of outer products Λ=∑i=1ν0zizi⊤ is a D×D random positive semidefinite matrix. It follows a Wishart distribution with ν0 degrees of freedom and scale Λ0, written Λ∼W(ν0,Λ0).
Let SD denote the set of D×D symmetric positive definite matrices. For Λ∈SD, the Wishart pdf is,
The parameters are: ν0>D−1 degrees of freedom (which must exceed D−1 for the distribution to be proper) and Λ0∈SD, the scale matrix. The mean and mode are,
In the univariate case D=1: W(λ∣ν0,ν0−1λ0)=χ2(ν0,λ0), which confirms the connection to the scaled chi-squared distribution.
The Wishart distribution plays a key role in two different settings. In frequentist statistics, it is the sampling distribution of the precision matrix estimated from multivariate normal data. In Bayesian statistics, it is the conjugate prior for the precision matrix of a multivariate normal, as we will see next.
Source
torch.manual_seed(305)
ν0 = torch.tensor(4.)
Λ0 = torch.eye(2) / ν0
Λs = Wishart(ν0, covariance_matrix=Λ0).sample(sample_shape=(5, 5))
fig, axs = plt.subplots(5, 5, figsize=(8, 8), sharex=True, sharey=True)
for i in range(5):
for j in range(5):
plot_cov(torch.inverse(Λs[i, j]), ax=axs[i, j])
plot_cov(torch.eye(2), ax=axs[i, j], color='k')
axs[i, j].set_xlim(-4, 4)
axs[i, j].set_ylim(-4, 4)
axs[i, j].set_aspect(1)
for i in range(5):
axs[i, 0].set_ylabel(r"$x_2$")
axs[-1, i].set_xlabel(r"$x_1$")
plt.tight_layout()
In the last step we used the identity (xn−μ)⊤Λ(xn−μ)=Tr(Λ(xn−μ)(xn−μ)⊤) to consolidate the exponential. The result has exactly the form of a Wishart density, so the posterior is,
The degrees of freedom simply accumulate: each new observation adds 1 to νN, increasing our certainty about Λ. The posterior scale ΛN is the inverse of the sum of the prior inverse scale and the data scatter matrix ∑n(xn−μ)(xn−μ)⊤. In the large data limit, the posterior mean νNΛN converges to (N1∑n(xn−μ)(xn−μ)⊤)−1, the inverse of the sample covariance — as we would expect.
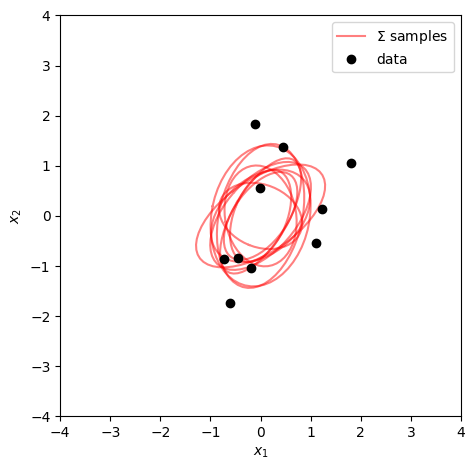
When it is more natural to parameterize in terms of the covariance Σ rather than the precision Λ, we use the inverse Wishart distribution. It is defined simply by a change of variables: if Λ∼W(ν0,Λ0), then Σ=Λ−1 follows an inverse Wishart distribution,
The scale matrix Σ0 can be interpreted as a prior sum of squared deviations, and ν0 controls how tightly concentrated the prior is around ν0−D−1Σ0. In the univariate case D=1: IW(σ2∣ν0,ν0σ02)=χ−2(ν0,σ02), recovering the scaled inverse chi-squared from Lecture 1.
Source
torch.manual_seed(305)
N = 10
X = MultivariateNormal(torch.zeros(2), torch.eye(2)).sample((N,))
ν0 = torch.tensor(1.0)
Λ0 = torch.eye(2)
νN = ν0 + N
ΛN = torch.inverse(torch.inverse(Λ0) + X.T @ X)
Λ_samp = Wishart(νN, ΛN).sample((10,))
Σ_samp = torch.inverse(Λ_samp)
fig, ax = plt.subplots()
ax.set_aspect(1)
for i, Σ in enumerate(Σ_samp):
plot_cov(Σ, ax=ax, color='r', alpha=0.5,
label=r"$\Sigma$ samples" if i == 0 else None)
ax.plot(X[:, 0], X[:, 1], 'ko', markersize=6, label="data")
ax.set_xlim(-4, 4)
ax.set_ylim(-4, 4)
ax.set_xlabel(r"$x_1$")
ax.set_ylabel(r"$x_2$")
ax.legend()
plt.tight_layout()
In the most general setting, both μ and Σ are unknown. Following the same strategy as Lecture 1 for the univariate case, we construct a joint conjugate prior over (μ,Σ). The key idea is to express the joint prior as a product p(μ,Σ)=p(μ∣Σ)p(Σ), choosing each factor to be conjugate in a compatible way.
Specifically, we set the prior on the covariance to be inverse Wishart and — crucially — make the prior on the mean conditional on the covariance: μ∣Σ∼N(μ0,Σ/κ0). This coupling between the mean and covariance priors, where the uncertainty in μ scales with Σ/κ0, is what makes the joint prior conjugate. The result is the normal-inverse-Wishart (NIW) distribution,
The four hyperparameters have natural interpretations: μ0 is the prior mean, κ0 is the mean confidence (how many pseudo-observations worth of information we have about the mean), ν0 is the degrees of freedom for the covariance, and Σ0 is the prior scale for the covariance.
Just as in the univariate case (where the marginal of the mean under a normal-inverse-chi-squared posterior was a Student’s t distribution), the posterior marginal of μ under the NIW is a multivariate Student’s t.
The Student’s t distribution arises because we are averaging a Gaussian over a random covariance drawn from an inverse Wishart — the extra uncertainty about Σ inflates the tails of the marginal compared to a pure Gaussian. The multivariate Student’s t distribution with ν degrees of freedom, location μ, and scale matrix Σ has density,
where Δ2=(x−μ)⊤Σ−1(x−μ) is the squared Mahalanobis distance. When ν is large, the term [1+Δ2/ν]−(ν+D)/2 converges to e−Δ2/2 and the Student’s t approaches a Gaussian. When ν is small, the distribution has heavier tails than a Gaussian. The mean of the multivariate Student’s t is μ and the covariance is ν−2νΣ (for ν>2) — the extra factor of ν/(ν−2)>1 reflects the heavier tails.
In our posterior, the effective degrees of freedom νN−D+1=ν0+N−D+1 grow with the number of observations, so the posterior predictive distribution converges to a Gaussian as N→∞, as we would expect when we become certain about Σ.
The multivariate normal distribution is the cornerstone of high-dimensional probabilistic modeling. Its key analytical properties — the ability to marginalize and condition in closed form, the Schur complement formula for conditional means and variances, and the Woodbury identity for efficient precision-form updates — appear repeatedly throughout the course. The conjugate prior framework generalizes naturally from the scalar case: the Wishart and inverse-Wishart distributions are the natural conjugates for the precision and covariance respectively, and the normal-inverse-Wishart prior gives a joint conjugate for unknown mean and covariance. The posterior marginal of the mean is a multivariate Student’s t, reflecting additional uncertainty from integrating out the unknown covariance.