The previous chapter introduced mixture models and two inference algorithms: K-Means (MAP via hard assignments) and a preview of EM (soft assignments via responsibilities). In this chapter we derive EM carefully and understand what it is optimising and why it works.
The key idea: rather than maximising the often-intractable marginal log-likelihood directly, EM iteratively constructs and maximises a tractable lower bound — the Evidence Lower Bound (ELBO) — by alternating between:
E-step: set the auxiliary distribution to the posterior , which makes the bound tight.
M-step: with fixed, maximise the ELBO over the parameters , which increases the marginal log-likelihood.
Topics covered:
The marginal log-likelihood and why EM can outperform gradient ascent
Jensen’s inequality and the ELBO
KL divergence and the E-step optimality condition
Full derivation of E-step and M-step for Gaussian and general exponential-family mixture models
Code: tracking the ELBO and marginal log-likelihood across EM iterations
Source
import torch
import torch.distributions as dist
import matplotlib.pyplot as plt
palette = list(plt.cm.tab10.colors)What is EM Optimising?¶
The Marginal Log-Likelihood¶
In the Bayesian mixture model, the parameters are and each data point has a latent assignment . We want to find parameters that maximise the marginal log-likelihood (with a log-prior acting as regulariser):
For discrete mixtures with small we can evaluate this sum exactly, so in principle we could do gradient ascent on .
Why prefer EM? EM exploits the structure of the model to obtain closed-form updates — no step-size tuning needed — and typically converges in far fewer iterations than gradient ascent on the marginal likelihood.
Review: Joint Distribution¶
The generative model gives:
The Evidence Lower Bound (ELBO)¶
Jensen’s Inequality¶
Jensen’s inequality states that for any concave function and random variable :
with equality if and only if is constant (or is linear). Since is concave, we have .
Deriving the ELBO¶
Introduce an auxiliary distribution over the discrete variable (any distribution with the same support):
The bound is the ELBO. It holds for any choice of , and EM can be viewed as coordinate ascent on the ELBO over the joint space .
The KL Divergence and the E-Step¶
KL Divergence¶
The Kullback-Leibler divergence between distributions and is:
with equality if and only if (almost everywhere). It is not symmetric, so it is not a metric.
The ELBO–KL Decomposition¶
We can rewrite the ELBO by adding and subtracting inside the expectation:
Since KL , this confirms .
E-Step¶
Maximising over (with fixed) amounts to minimising the KL divergence to the posterior. The unique minimiser is:
After the E-step, the KL terms vanish and the bound is tight:
For the Gaussian mixture model, setting gives the responsibilities:
The M-Step¶
Gaussian Mixture Model¶
With fixed to the responsibilities , the ELBO as a function of (absorbing constants) is:
Collecting terms for a single :
where the pseudo-observations accumulate the soft sufficient statistics:
Setting the gradient to zero:
In the improper uniform prior limit (): — the responsibility-weighted sample mean.
The proportions update as .
EM as a Minorize-Maximize (MM) Algorithm¶
Each EM iteration:
E-step (minorize): construct the ELBO , which touches the marginal log-likelihood at .
M-step (maximize): find .
Because and , the marginal log-likelihood is guaranteed to increase (or stay the same) at every iteration.
EM for General Exponential-Family Mixtures¶
Generic M-Step¶
For an exponential-family likelihood with conjugate prior , the ELBO restricted to is:
Setting the gradient to zero: , so
Gradient of the Log Normalizer = Expected Sufficient Statistics¶
Why is well defined? Differentiating the log normalizer:
So maps natural parameters to expected sufficient statistics. For a minimal exponential family this map is bijective, so the M-step reduces to: find the natural parameters that match the responsibility-weighted average of the sufficient statistics.
| Model | M-step update | ||
|---|---|---|---|
| Gaussian () | |||
| Bernoulli | |||
| Poisson |
torch.manual_seed(305)
N, K, D = 300, 3, 2
# True parameters
π_true = torch.tensor([0.3, 0.4, 0.3])
μ_true = torch.tensor([[-3., -1.], [1., 3.], [3., -2.]])
z_true = dist.Categorical(π_true).sample((N,))
x = μ_true[z_true] + torch.randn(N, D)
def em_gmm(x, K, num_iters=40, seed=0):
"""EM for isotropic-unit-variance GMM, tracking ELBO and marginal LL.
At each iteration we record:
elbo_E -- ELBO right after the E-step (equals marginal LL)
ll_E -- marginal log-likelihood after E-step (= elbo_E)
elbo_M -- ELBO right after the M-step (≤ new marginal LL)
ll_M -- marginal log-likelihood after M-step
"""
torch.manual_seed(seed)
# Initialise centroids by picking K random data points
μ = x[torch.randperm(len(x))[:K]].clone().float()
π = torch.ones(K) / K
def e_step(μ, π):
log_p = torch.stack(
[dist.MultivariateNormal(μ[k], torch.eye(D)).log_prob(x) + π[k].log()
for k in range(K)], dim=1) # (N, K)
log_Z = torch.logsumexp(log_p, dim=1) # (N,)
ω = torch.exp(log_p - log_Z.unsqueeze(1)) # (N, K)
return ω, log_Z.sum().item()
def m_step(ω):
N_k = ω.sum(0)
π = N_k / N
μ = (ω.T @ x) / N_k.unsqueeze(1)
return μ, π
def elbo(μ, π, ω):
val = 0.0
for k in range(K):
lp = dist.MultivariateNormal(μ[k], torch.eye(D)).log_prob(x) + π[k].log()
lq = torch.log(ω[:, k].clamp(min=1e-40))
val += (ω[:, k] * (lp - lq)).sum().item()
return val
records = []
for _ in range(num_iters):
ω, ll_E = e_step(μ, π)
elbo_E = ll_E # bound is tight after E-step
μ, π = m_step(ω)
_, ll_M = e_step(μ, π) # recompute LL with updated params
elbo_M = elbo(μ, π, ω) # ELBO with old q, new θ (may be loose)
records.append(dict(elbo_E=elbo_E, ll_E=ll_E,
elbo_M=elbo_M, ll_M=ll_M))
return μ, π, records
μ_em, π_em, records = em_gmm(x, K=3, num_iters=40)
print('Final means:')
for k in range(K):
print(f' k={k}: {μ_em[k].numpy().round(2)}')Final means:
k=0: [ 2.95 -2. ]
k=1: [-2.88 -0.93]
k=2: [1.07 3.12]
Source
iters = list(range(1, len(records) + 1))
elbo_E = [r['elbo_E'] for r in records]
ll_M = [r['ll_M'] for r in records]
elbo_M = [r['elbo_M'] for r in records]
fig, axes = plt.subplots(1, 2, figsize=(11, 4))
# ── Left: marginal LL vs ELBO per iteration ──────────────────────────────────
ax = axes[0]
ax.plot(iters, ll_M, 'o-', color='steelblue', label='Marginal LL (after M-step)', lw=2, ms=4)
ax.plot(iters, elbo_E, 's--', color='tomato',
label='ELBO = Marginal LL (after E-step)', lw=1.5, ms=4)
ax.plot(iters, elbo_M, '^:', color='goldenrod',
label='ELBO (after M-step, before next E-step)', lw=1.5, ms=4)
ax.set_xlabel('EM iteration')
ax.set_ylabel('Value')
ax.set_title('ELBO and marginal log-likelihood over EM')
ax.legend(fontsize=8)
# ── Right: zoom-in on first 10 iterations ────────────────────────────────────
ax = axes[1]
nshow = 10
ax.plot(iters[:nshow], ll_M[:nshow], 'o-', color='steelblue', lw=2, ms=5)
ax.plot(iters[:nshow], elbo_E[:nshow], 's--', color='tomato', lw=1.5, ms=5)
ax.plot(iters[:nshow], elbo_M[:nshow], '^:', color='goldenrod', lw=1.5, ms=5)
# Annotate the gap between ELBO_M and LL_M on iteration 1
it = 0
ax.annotate('', xy=(iters[it], ll_M[it]), xytext=(iters[it], elbo_M[it]),
arrowprops=dict(arrowstyle='<->', color='black', lw=1.5))
ax.text(iters[it] + 0.15, (ll_M[it] + elbo_M[it]) / 2,
'KL gap', fontsize=8, va='center')
ax.set_xlabel('EM iteration')
ax.set_ylabel('Value')
ax.set_title('First 10 iterations (zoomed)')
plt.tight_layout()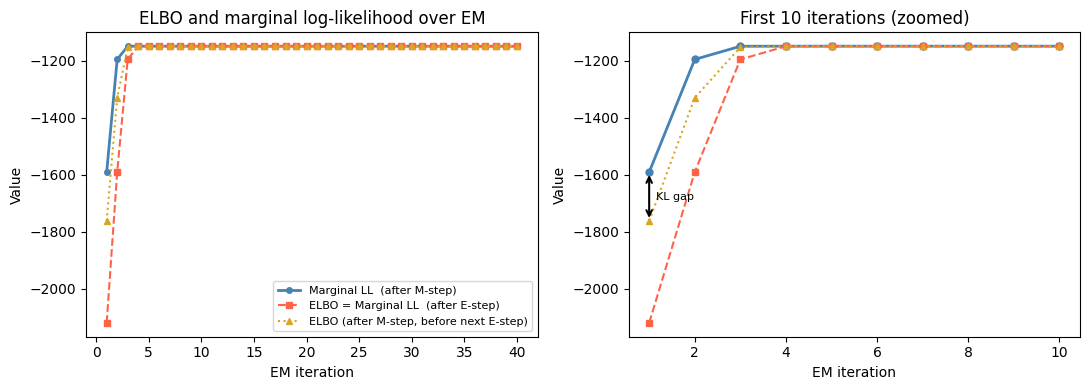
Conclusion¶
This chapter derived the EM algorithm from first principles:
| E-step | M-step | |
|---|---|---|
| Action | Set | Maximise ELBO over |
| Effect on ELBO | ELBO = marginal LL (bound tight) | ELBO increases |
| Effect on LL | No change (only changes) | Marginal LL increases |
Key takeaways:
The ELBO lower-bounds the marginal log-likelihood; the gap is the sum of KL divergences .
The E-step closes this gap entirely by setting to the exact posterior.
The M-step increases the bound (and hence the likelihood) by finding better parameters given fixed responsibilities.
For exponential-family likelihoods, the M-step has a closed form: find natural parameters matching the responsibility-weighted sufficient statistics.
EM is guaranteed to monotonically increase the marginal log-likelihood and converges to a local maximum (global in some special cases).
Like K-Means, EM is sensitive to initialisation; random restarts or K-Means++ initialisation are recommended in practice.
- Bishop, C. M. (2006). Pattern recognition and machine learning. Springer.