Bayesian GLMs#
We’ve taken our first steps toward becoming Bayesian statisticians! We learned about conjugate priors, which permit exact inference for simple probabilistic models like the beta-Bernoulli model. However, we found that more complex models require some form of approximate posterior inference. MCMC methods offer a general-purpose solution to approximate inference, allowing us to construct Markov chains for which the stationary distribution is the posterior distribution of interest. Now, let’s put those ideas into practice by developing MCMC algorithms for Bayesian GLMs.
Setup#
%%capture
!pip install jaxtyping
import torch
import matplotlib.pyplot as plt
from fastprogress import progress_bar
from jaxtyping import Array, Float
from mpl_toolkits.axes_grid1 import make_axes_locatable
from typing import Callable, Tuple
from torch.distributions import Bernoulli, Gamma, MultivariateNormal, Normal, StudentT, \
Uniform
Bayesian Logistic Regression#
Model#
Let \(y_i \in \{0,1\}\) denote a binary observation and \(x_i \in \mathbb{R}^p\) a corresponding vector of covariates. Let \(\beta \in \mathbb{R}^p\) denote the weights of our GLM. Our probabilistic model is,
where \(f: \mathbb{R} \mapsto (0,1)\) is the mean function. The canonical mean function is \(f(a) = \sigma(a) = 1 / (1+e^{-a})\), the logistic function, but we will consider other link functions in this lecture as well.
Our goal is to approximate the posterior distribution \(p(\beta \mid y, X)\). Unfortuantely, the posterior doesn’t have a simple closed form since the Bernoulli likelihood is not conjugate with the Gaussian prior. Instead, we will develop MCMC algorithms to draw samples from the posterior distribution, at least asymptotically.
Generate Synthetic Data#
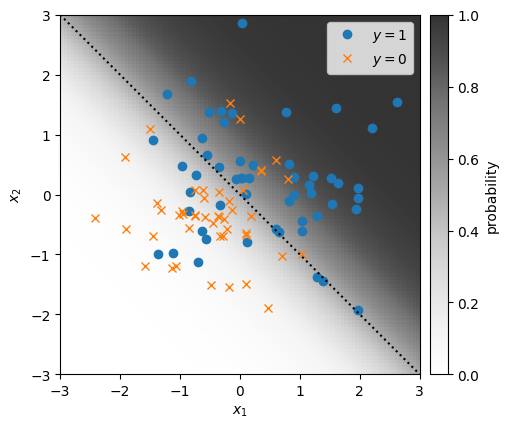
Let’s start by generating some synthetic data from a Bernoulli GLM with true weights \(\beta^\star\). To make it easy to visualize, we’ll use two dimensional features, so our weights will be three dimensional when we include an intercept.
torch.manual_seed(305 + ord('b'))
# Set constants
num_features = 3 # first "feature" is all ones
num_data = 100 # number of data points to sample
mean_func = torch.sigmoid # canonical mean function
prior_scale = 3. # std of Gaussian prior \gamma^{-1/2}
# Fix true weights. Sample features, and responses.
true_weights = 1.5 * torch.tensor([0., 1., 1.])
features = torch.column_stack([
torch.ones(num_data),
Normal(0, 1).sample((num_data, num_features-1))
])
responses = Bernoulli(mean_func(features @ true_weights)).sample()
def plot_sample(responses: Float[Array, "num_data"],
features: Float[Array, "num_data num_features"],
weights: Float[Array, "num_features"],
mean_func: Callable,
lim=(-3, 3),
num_points=100,
figsize=(5, 5)
) -> None:
""" Helper function to plot the samples and weights of a Bernoulli GLM.
"""
x1, x2 = torch.meshgrid(torch.linspace(*lim, num_points),
torch.linspace(*lim, num_points))
X = torch.column_stack([
torch.ones(num_points**2),
x1.ravel(),
x2.ravel()
])
probs = mean_func(X @ weights)
fig, ax = plt.subplots(1, 1, figsize=figsize)
im = plt.imshow(probs.reshape((num_points, num_points)),
cmap="Greys", vmin=-0, vmax=1,
alpha=0.8,
extent=lim + tuple(reversed(lim)))
plt.plot(features[responses==1, 1], features[responses==1, 2],
'o', markersize=6, label="$y=1$")
plt.plot(features[responses==0, 1], features[responses==0, 2],
'x', markersize=6, label="$y=0$")
# Draw the true decision boundary
x1s = torch.linspace(*lim, 100)
x2s = -(weights[0] + weights[1] * x1s) / weights[2]
plt.plot(x1s, x2s, ':k')
# Clean up the axes
plt.xlabel(r"$x_1$")
plt.ylabel(r"$x_2$")
plt.xlim(lim)
plt.ylim(lim)
plt.legend()
# Colorbar
divider = make_axes_locatable(ax)
cax = divider.new_horizontal(size="5%", pad=0.1)
fig.add_axes(cax)
plt.colorbar(im, cax=cax, label="probability")
plot_sample(responses, features, true_weights, mean_func)
/usr/local/lib/python3.10/dist-packages/torch/functional.py:504: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:3526.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
Log Probability#
Write a function to compute the log joint probability, \(p(y, \beta \mid X)\).
def log_joint(responses: Float[Array, "num_data"],
features: Float[Array, "num_data num_features"],
weights: Float[Array, "num_features"],
mean_func: Callable,
prior_scale: float) -> float:
""" Compute the log joint probability of the responses and
weights given the features. Assume the weights have a Gaussian
prior with mean zero and the specified scale.
Returns
-------
Log joint probability of the responses and weights.
"""
lp = Normal(0, prior_scale).log_prob(weights).sum()
lp += Bernoulli(mean_func(features @ weights)).log_prob(responses).sum()
return lp
Metropolis-Hastings#
First, let’s implement a simple Metropolis-Hasting (MH) algorithm with a symmetric Gaussian proposal distribution,
where \(\nu\) is the standard deviation of the proposal. This is called random walk Metropolis-Hastings (RWMH).
Implement a single RWMH step#
def rwmh_step(log_prob: Callable,
curr_weights: Float[Array, "num_features"],
curr_log_prob: float,
proposal_scale: float) -> \
Tuple[Float[Array, "num_features"], float]:
""" Perform one step of random walk Metropolis-Hastings starting
from the current weights and using a symmetric Gaussian proposal
with the specified scale.
Arguments
---------
log_prob: a function that takes in weights and outputs an unnormalized
log density. In our case, this function will return the log joint
probability of the weights and responses. As a function of the weights,
this is equal to the log posterior probability up to an unknown
normalizing constant.
curr_weights: the current parameters
curr_log_prob: the current log probability (so we don't have to re-evaluate)
proposal_scale: the standard deviation of the spherical Gaussian proposal
Returns
-------
Next sample of the weights and the corresponding log prob
"""
prop_weights = Normal(curr_weights, proposal_scale).sample()
prop_log_prob = log_prob(prop_weights)
accept = torch.log(Uniform(0, 1).sample()) < prop_log_prob - curr_log_prob
return (prop_weights, prop_log_prob) if accept else (curr_weights, curr_log_prob)
Implement the MCMC loop#
def rwmh(log_prob: Callable,
init_weights: Float[Array, "num_features"],
proposal_scale: float,
num_iters: int = 10000,
) -> \
Tuple[Float[Array, "num_samples num_features"], Float[Array, "num_samples"]]:
""" Run the random walk MH algorithm from the given starting point and for the
specified number of iterations.
Returns
-------
Array of weight samples and corresponding log joint probabilities.
"""
# Initialize the loop
curr_weights = init_weights
curr_log_prob = log_prob(curr_weights)
weight_samples = [curr_weights]
log_probs = [curr_log_prob]
for itr in progress_bar(range(num_iters)):
curr_weights, curr_log_prob = rwmh_step(log_prob,
curr_weights,
curr_log_prob,
proposal_scale)
weight_samples.append(curr_weights)
log_probs.append(curr_log_prob)
return torch.stack(weight_samples), torch.stack(log_probs)
Let ‘er rip!#
# Make a log prob function that closes over the observations and hyperparams
log_prob = lambda weights: log_joint(responses,
features,
weights,
mean_func,
prior_scale)
# Run RWMH starting from \beta = 0
init_weights = torch.zeros(num_features)
weight_samples, log_probs = rwmh(log_prob, init_weights, proposal_scale=0.1)
Plot the results#
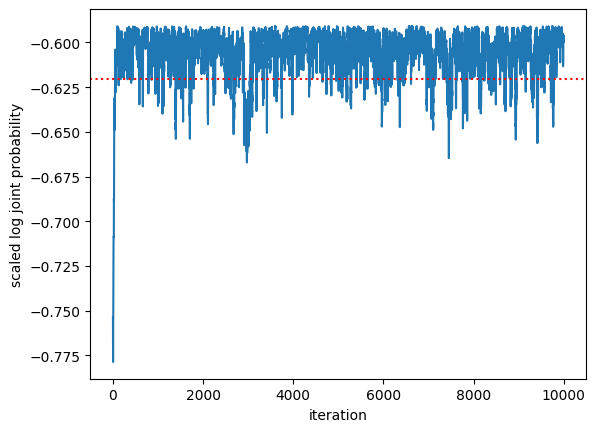
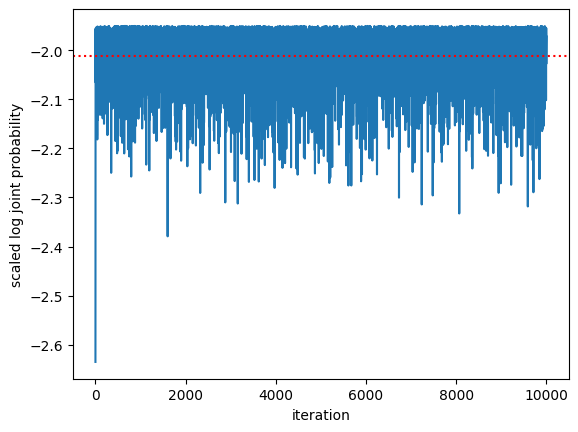
First look at the log joint probability as a function of MCMC iteration. It should go up and then stabilize. How does it compare to the log joint probability evaluated at the true weights, \(\beta^\star\)?
plt.plot(log_probs / num_data)
plt.axhline(log_prob(true_weights) / num_data, color='r', ls=':')
plt.xlabel("iteration")
plt.ylabel("scaled log joint probability")
Text(0, 0.5, 'scaled log joint probability')
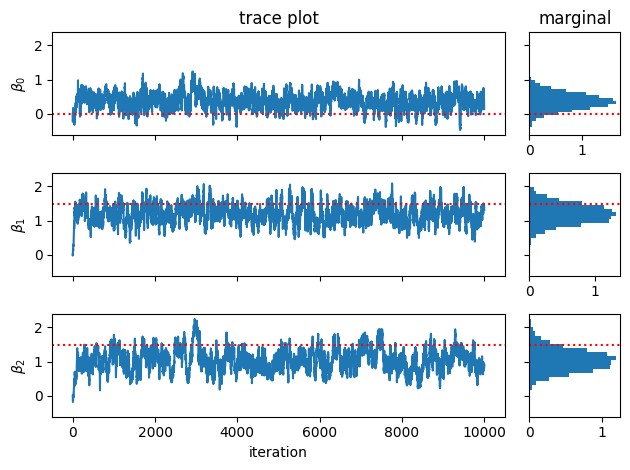
Now make a trace plot of the weights acros MCMC iteration.
fig, axs = plt.subplots(num_features, 2, width_ratios=(5,1), sharey=True)
for j in range(num_features):
# Plot the trace of the samples
axs[j, 0].plot(weight_samples[:, j])
axs[j, 0].axhline(true_weights[j], color='r', ls=':')
axs[j, 0].set_ylabel(r"$\beta_{}$".format(j))
if j < num_features - 1: axs[j,0].set_xticklabels([])
# Plot a histogram of samples
axs[j, 1].hist(weight_samples[:, j], 20, orientation="horizontal", density=True)
axs[j, 1].axhline(true_weights[j], color='r', ls=':')
axs[0, 0].set_title("trace plot")
axs[0, 1].set_title("marginal")
axs[-1,0].set_xlabel("iteration")
plt.tight_layout()
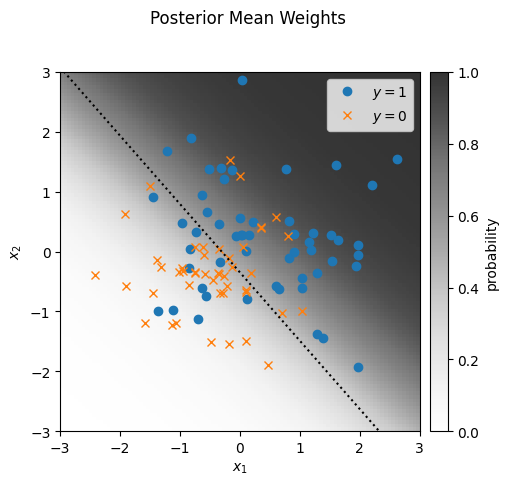
Finally, let’s approximate the posterior mean, \(\bar{\beta}\), and plot the data and predicted probabilities under \(\bar{\beta}\).
mean_weights = weight_samples[100:].mean(axis=0)
plot_sample(responses, features, mean_weights, mean_func)
_ = plt.suptitle("Posterior Mean Weights")
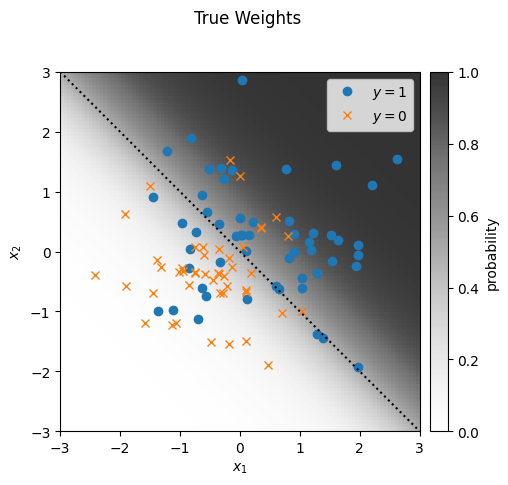
plot_sample(responses, features, true_weights, mean_func)
_ = plt.suptitle("True Weights")
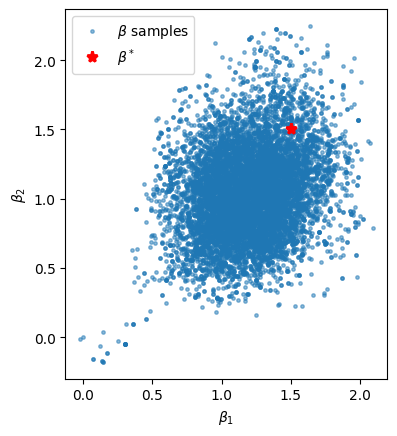
Finally, let’s look at the MCMC estimate of the posterior pairwise marginal \(p(\beta_1, \beta_2 \mid y, X)\) to see how correlated they are.
Question: Before running the cell below, do you expect the weights to be correlated under the posterior? Explain your answer.
plt.scatter(weight_samples[:, 1], weight_samples[:, 2], s=6, alpha=0.5, label=r"$\beta$ samples")
plt.plot(true_weights[1], true_weights[2], 'r*', ms=8, mew=2, label=r"$\beta^*$")
plt.xlabel(r"$\beta_1$")
plt.ylabel(r"$\beta_2$")
plt.legend()
plt.gca().set_aspect(1)
Exercise#
Now go back and play with the hyperparameters.
What if you make the true weights larger — is the posterior more concentrated around the true weights?
What happens if you change the prior variance?
What happens if you change the proposal variance?
Robust Bayesian Linear Regression#
Now let’s go on a little side quest and talk about robust linear regression. It will be a good excuse to introduce the concept of augmentation and implement a Gibbs sampling algorithm. Then we’ll come back to Bayesian GLMs and apply the same ideas.
Primer: Bayesian Linear Regression with Heteroskedastic Noise#
Suppose you have observations \(y_i \in \mathbb{R}\) and features \(x_i \in \mathbb{R}^p\). Unlike the ordinary linear regression setup, assume you have heteroskedastic noise with known variance, \(\sigma_i^2\) for data points \(i=1,\ldots, n\).
The joint probability is,
Exercise#
Derive the posterior distribution \(p(\beta \mid y, X, \sigma^2)\).
Solution#
Solution
The posterior is proportional to the joint probability,
where
We can rewrite this as a multivariate normal distribution by completing the square,
where
The posterior mean can be written in terms of \(x\) and \(y\) in compact form,
where \(W = \mathrm{diag}((w_1, \ldots, w_n))\).
We recognize this as the weighted least squares estimate with ridge regularization!
Robust Regression with Students’ T Noise#
The model above makes the strong and often unreasonable assumption that we know the noise variance for each data point. A more reasonable assumption is to consider a model with heavy-tailed noise, like the following,
where \(\mathrm{St}(\mu, \sigma_0^2, \nu)\) denotes the Students’ t distribution with mean \(\mu\), scale \(\sigma_0\), and \(\nu\) degrees of freedom. Its density is,
where \(\Delta^2 = \left(\tfrac{y - \mu}{\sigma_0} \right)^2\) is the squared Mahalanobis distance. Its mean is \(\mu\) and its variance is \(\frac{\nu}{\nu + 2} \sigma_0^2\).
Unfortunately, the Student’s t distribution is not conjugate with the Gaussian prior (convince yourself).
Student’s t as a scale-mixture of Gaussians#
However, here’s a nifty trick! The Student’s t density can be written as a scale-mixture of Gaussians,
where \(\mathrm{IGa}\) denotes the inverse gamma distribution, which has density
When \(a = \nu/2\) and \(b = \nu \sigma_0^2 /2\), it has mean \(\mathbb{E}[\sigma^2] = \frac{\nu}{\nu - 2} \sigma_0^2\) (for \(\nu > 2\)) and the variance shrinks as \(\nu\) increases.
Notes:
The inverse gamma is equivalent to a scaled inverse chi-squared distribution with degrees of freedom \(\nu\) and scale \(\sigma_0^2\).
If \(\sigma \sim \mathrm{IGa}(a, b)\) then \(\sigma^{-1} \sim \mathrm{Ga}(a, b)\), so we can also think of the Student’s t distribution as a continuous mixture of Gaussians with gamma distributed precisions.
Augmentation Tricks#
We can use the integral representation of the Student’s t distribution to write our joint distribution as a marginal of an augmented model. To be precise, we can write the joint distribution above as,
The nice thing about Monte Carlo is that if we can draw samples from the posterior distribution of the augmented model, \(p(\beta, \sigma \mid y, X)\), then we can simply discard our samples of \(\sigma\) when calculating posterior expectations that are functions of \(\beta\). That is,
It may sound strictly harder to draw samples from the posterior of \(\beta\) and \(\sigma^2\) than from the posterior of \(\beta\) alone, but that’s not always the case! For example, in this augmented model, note that the conditional distributions have nice closed forms. In particular,
This is exactly the Bayesian linear regression model with known, heteroskedastic noise that we solved above!
Exercise#
Derive the conditional distribution \(p(\sigma_i^2 \mid y_i, x_i, \beta)\)
Solution#
Solution
where
In other words, the inverse gamma distribution is a conjugate prior for the variance of a normal distribution (with fixed mean).
Generate Synthetic Data#
Now let’s generate some synthetic data from the robust linear regression model. Here, we’ll use just an intercept and a slope, so \(\beta \in \mathbb{R}^2\).
torch.manual_seed(305 + ord('b'))
# Set constants
num_features = 2 # first "feature" is all ones
num_data = 20 # number of data points to sample
noise_scale = 1.0 # scale of the Student's t noise
noise_dof = 2.0 # degrees of freedom of the Student's t noise
prior_scale = 3. # std of Gaussian prior \gamma^{-1/2}
# Fix true weights. Sample features, and responses.
true_weights = torch.tensor([0., 1.])
features = torch.column_stack([
torch.ones(num_data),
Normal(0, 1).sample((num_data, num_features-1))
])
# Sample from a model with a mixture of Gaussians noise distribution
responses = StudentT(noise_dof, features @ true_weights, noise_scale).sample()
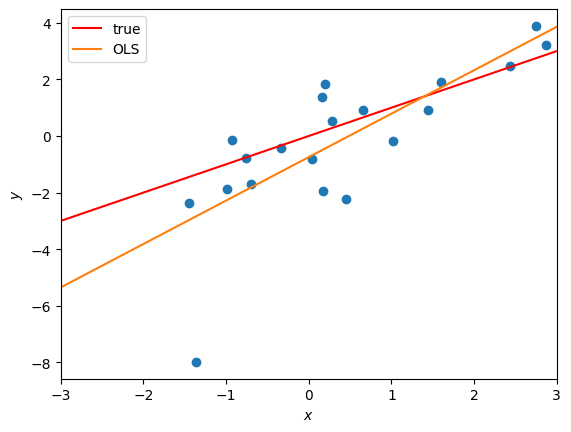
# Plot the data and overlay the OLS estimate of the weights
def plot_robust_reg_data(responses,
features,
true_weights,
weights_labels=(),
lim=(-3, 3)):
plt.plot(features[:, 1], responses, 'o')
xs = torch.linspace(*lim, 100)
plt.plot(xs, true_weights[0] + true_weights[1] * xs, '-r', label="true")
for weights, label in weights_labels:
plt.plot(xs, weights[0] + weights[1] * xs, label=label)
plt.xlim(lim)
plt.xlabel(r"$x$")
plt.ylabel(r"$y$")
plt.legend()
ols_weights = torch.linalg.solve(features.T @ features, features.T @ responses)
plot_robust_reg_data(responses, features, true_weights, [(ols_weights, "OLS")])
Implement a Gibbs sampler#
Now implement a Gibbs sampling algorithm to approximate the posterior distribution of the weights in the robust regression model. Specifically, write functions to sample the weights given noise variances and the noise variances given the weights. The Gibbs sampling algorithm will alternate between these two steps.
def log_joint(responses: Float[Array, "num_data"],
features: Float[Array, "num_data num_features"],
weights: Float[Array, "num_features"],
prior_scale: float,
noise_dof: float,
noise_scale: float) -> float:
""" Compute the log joint probability of the robust regression model """
lp = Normal(0, prior_scale).log_prob(weights).sum()
lp += StudentT(noise_dof, features @ weights, noise_scale).log_prob(responses).sum()
return lp
# Test that it runs
log_joint(responses, features, true_weights, prior_scale, noise_dof, noise_scale)
tensor(-40.2235)
def gibbs_step_weights(responses: Float[Array, "num_data"],
features: Float[Array, "num_data num_features"],
noise_variances: Float[Array, "num_data"],
prior_scale: float) -> \
Float[Array, "num_features"]:
""" Perform a Gibbs step to sample the weights from their conditional.
Returns
-------
Next sample of the weights
"""
num_features = features.shape[1]
J = 1 / prior_scale**2 * torch.eye(num_features)
J += torch.einsum("n,nj,nk->jk", 1/noise_variances, features, features)
h = torch.einsum("n,n,nj->j", 1/noise_variances, responses, features)
mu = torch.linalg.solve(J, h)
return MultivariateNormal(mu, precision_matrix=J).sample()
# Test that it runs
dummy_noise_vars = torch.ones(num_data)
gibbs_step_weights(responses, features, dummy_noise_vars, prior_scale)
tensor([-1.1203, 1.7094])
def gibbs_step_noise_vars(responses: Float[Array, "num_data"],
features: Float[Array, "num_data num_features"],
weights: Float[Array, "num_features"],
noise_dof: float,
noise_scale: float) -> \
Float[Array, "num_dat"]:
""" Perform a Gibbs step to sample the auxiliary noise variances from their conditionals.
Note that the noise variances are conditionally independent and hence can be sampled
in parallel.
Returns
-------
Next sample of the noise variances.
"""
concentration = 0.5 * (noise_dof + 1)
preds = features @ weights
rate = 0.5 * (noise_dof * noise_scale**2 + (responses - preds)**2)
return 1 / Gamma(concentration, rate).sample()
# Test that it runs
gibbs_step_noise_vars(responses, features, true_weights, noise_dof, noise_scale)
tensor([ 0.9094, 1.2934, 49.7823, 0.8115, 2.1487, 2.4824, 0.3803, 17.6953,
0.2016, 11.7235, 4.3357, 0.9562, 0.5754, 0.8171, 0.2200, 1.0080,
4.2905, 2.2647, 0.6595, 0.8128])
def gibbs(responses: Float[Array, "num_data"],
features: Float[Array, "num_data num_features"],
init_weights: Float[Array, "num_features"],
prior_scale: float,
noise_dof: float,
noise_scale: float,
num_iters: int = 10000,
) -> \
Tuple[Float[Array, "num_samples num_features"], Float[Array, "num_samples"]]:
""" Run the random walk MH algorithm from the given starting point and for the
specified number of iterations.
Returns
-------
Array of weight samples and corresponding log joint probabilities.
"""
# Helper function to compute log prob as a function of the weights
lp = lambda weights: log_joint(responses,
features,
weights,
prior_scale,
noise_dof,
noise_scale)
# Initialize the loop
weights = init_weights
weight_samples = [weights]
log_probs = [lp(weights)]
for itr in progress_bar(range(num_iters)):
noise_vars = gibbs_step_noise_vars(responses, features, weights, noise_dof, noise_scale)
weights = gibbs_step_weights(responses, features, noise_vars, prior_scale)
weight_samples.append(weights)
log_probs.append(lp(weights))
return torch.stack(weight_samples), torch.stack(log_probs)
Let ‘er rip!#
# Run Gibbs starting from \beta = 0
init_weights = torch.zeros(num_features)
weight_samples, log_probs = gibbs(responses, features, init_weights, prior_scale, noise_dof, noise_scale)
Plot the results#
plt.plot(log_probs / num_data)
plt.axhline(log_joint(responses, features, true_weights, prior_scale, noise_dof, noise_scale) / num_data, color='r', ls=':')
plt.xlabel("iteration")
plt.ylabel("scaled log joint probability")
Text(0, 0.5, 'scaled log joint probability')
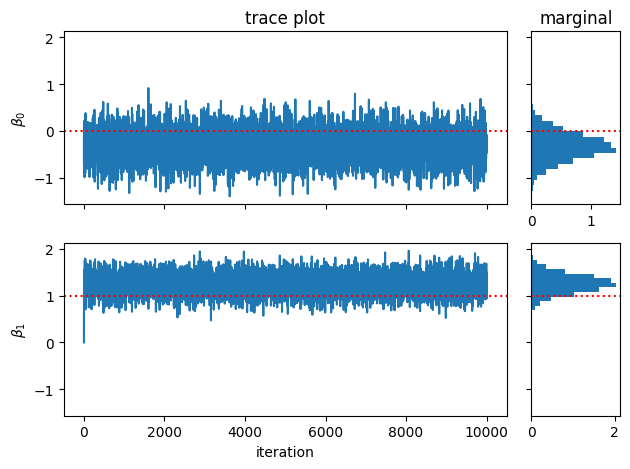
fig, axs = plt.subplots(num_features, 2, width_ratios=(5,1), sharey=True)
for j in range(num_features):
# Plot the trace of the samples
axs[j, 0].plot(weight_samples[:, j])
axs[j, 0].axhline(true_weights[j], color='r', ls=':')
axs[j, 0].set_ylabel(r"$\beta_{}$".format(j))
if j < num_features - 1: axs[j,0].set_xticklabels([])
# Plot a histogram of samples
axs[j, 1].hist(weight_samples[:, j], 20, orientation="horizontal", density=True)
axs[j, 1].axhline(true_weights[j], color='r', ls=':')
axs[0, 0].set_title("trace plot")
axs[0, 1].set_title("marginal")
axs[-1,0].set_xlabel("iteration")
plt.tight_layout()
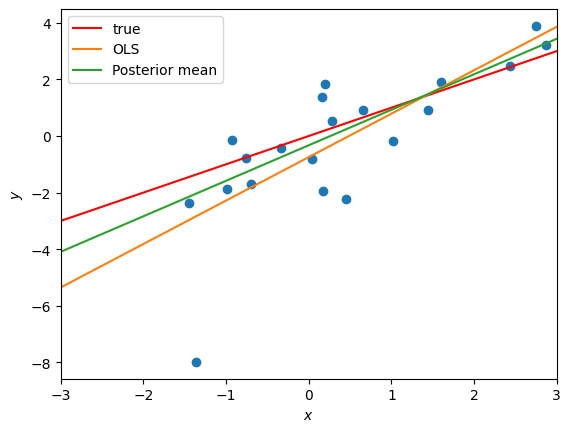
Plot the posterior mean of the weights. Is it any closer to the true weights than the OLS?
mean_weights = weight_samples.mean(axis=0)
plot_robust_reg_data(responses, features, true_weights,
[(ols_weights, "OLS"),
(mean_weights, "Posterior mean")])
Bayesian Probit Regression#
There are cool augmentation tricks for Bayesian GLMs too! For example, consider a Bernoulli GLM with the probit link function,
i.e., the normal CDF. Like the logistic function, the normal CDF is a monotonically increasing function that defines a bijective mapping from \(\mathbb{R} \mapsto (0,1)\). With this mean function, the Bernoulli GLM likelihood is,
Albert and Chib [AC93] noted that we can rewrite this likelihood using the integral representation of the mean function, together with a few handy transformations. Namely,
Substituting these expressions into the likelihood above,
where
In other words, we can view the Bernoulli likelihood with probit link as the marginal of a joint distribution, \(p(y_i, z_i \mid x_i, \beta)\). In this particular joint distribution, \(y_i\) is deterministic given \(z_i\).
Another way to think about this augmented model is that we only observe the sign of a latent variable \(z_i\) (where \(y_i=0\) if \(z_i\) is negative, and \(y_i=1\) if it is positive). The latent variable is itself a noisy perturbation of the linear model’s prediction, \(\beta^\top x_i\). The challenge is, given these observations of the sign, to estimate the underlying weights \(\beta\).
Exercise#
Show that the conditional distribution of the latent variable \(z_i\) in the augmented model is a truncated normal distribution.
Show that the conditional distribution of the weights given the latent variables \(z_i\) is multivariate normal.
Implement a Gibbs sampling algorithm to draw samples from the joint distribution \(p(z, \beta \mid y, X)\).
Augmentation Schemes for Bayesian Logistic Regression#
We can apply the same logic to the logistic regression case by viewing the logistic function as the CDF of a distribution on the real line. It turns out the corresponding distribution is the aptly named logistic distribution with pdf,
Then, we can interpret the Bernoulli likelihood with logistic mean function as a marginal of the auxiliary model,
Or, as with the probit model above,
The logistic distribution is heavier tailed than a Gaussian. In fact, its is closer to a Student’s t distribution with 9 degrees of freedom and slightly inflated scale, as shown below
zs = torch.linspace(-8, 8, 1000)
plt.plot(zs, torch.sigmoid(zs) * torch.sigmoid(-zs), lw=3, label="logistic")
plt.plot(zs, torch.exp(StudentT(9, 0, 1.55).log_prob(zs)), '--', label="St(0, 1.55, 9)", )
plt.plot(zs, torch.exp(Normal(0, 1).log_prob(zs)), label="normal")
plt.legend()
plt.xlabel(r"$z$")
plt.ylabel(r"$p(z)$")
Text(0, 0.5, '$p(z)$')
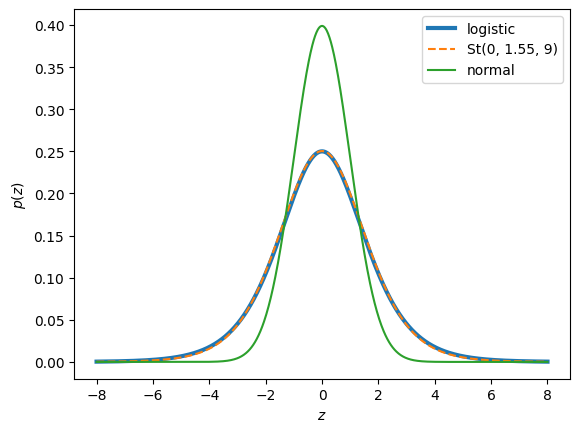
This motivates a simple approximation of \(z_i \sim \mathrm{St}(9, x_i^\top \beta, 1.55)\). Using this approximation, you can perform Gibbs sampling on the conjugate model, alternating between updating \(\beta\) from its Gaussian conditional, and updating \(z_i\) from its truncated Student’s t conditional.
Conclusion#
This lecture looks works through some actual implementations of MCMC algorithms and develops some useful tricks for Gibbs sampling via augmentation. There are some even better approaches out there for Gibbs sampling in logistic models, and we’ll explore them in the homework assignment!