Sparse GLMs#
One reason we like linear and generalized linear models is that the parameters are readily interpretable. The parameter \(\beta_j\) relates changes in covariate \(x_j\) to changes in the natural parameter of the response distribution. One common application of such models is for variable selection, finding a subset of covariates that are most predictive of the response. To that end, we would like our estimates, \(\hat{\mbbeta}\), to be sparse. When we have a vast number covariates — as in genome-wide association studies (GWAS) where we aim to predict a trait given thousands of single nucleotide polymorphisms (SNPs) in the genome — sparse solutions help focus our attention on the most relevant covariates.
Setup#
!pip install jaxtyping
Requirement already satisfied: jaxtyping in /Users/scott/anaconda3/lib/python3.10/site-packages (0.2.25)
Requirement already satisfied: typeguard<3,>=2.13.3 in /Users/scott/anaconda3/lib/python3.10/site-packages (from jaxtyping) (2.13.3)
Requirement already satisfied: numpy>=1.20.0 in /Users/scott/anaconda3/lib/python3.10/site-packages (from jaxtyping) (1.23.5)
Requirement already satisfied: typing-extensions>=3.7.4.1 in /Users/scott/anaconda3/lib/python3.10/site-packages (from jaxtyping) (4.4.0)
import matplotlib.pyplot as plt
import torch
from jaxtyping import Float
from torch import Tensor
from torch.distributions import Normal, Bernoulli
from typing import Tuple, Optional, Callable
/Users/scott/anaconda3/lib/python3.10/site-packages/tqdm/auto.py:22: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Lasso Regression#
Consider a linear Gaussian model,
for \(i = 1, \ldots,n\), where \(\beta_0\) is the intercept parameter, \(\mbx_i \in \reals^p\) are the covariates, and \(\mbbeta \in \reals^p\) are the weights. We factored out the intercept because we typically don’t regularize that parameter.
The Lasso yields sparse solutions for linear models like this by minimizing the (average) negative log likelihood subject to \(\ell_1\) regularization.
where \(\|\mbbeta\|_1 = \sum_{j=1}^p |\beta_j|\). Note that this is a convex objective function!
It’s tempting to just use vanilla gradient ascent to find the optimum,
where \(\alpha_t \in \reals_+\) is the step size at iteration \(t\).
Unfortunately, the Lasso objective it is not continuously differentiable: the gradient at \(\beta_j=0\) is discontinuous due to the absolute value in the \(\ell_1\) norm. What can we do instead?
You only live once… run gradient descent and hope for the best!
Use subgradient descent, taking a step in the direction of any subgradient of \(\cL\), but that approach can be much slower, with convergence rates of only \(\cO(1/\epsilon^2)\).
Use proximal gradient descent, which amounts to iterative soft thresholding for the Lasso problem. This has much better convergence rates, as we’ll discuss below.
Use coordinate descent, which works very well in practice, even if it’s harder to prove convergence rates.
Coordinate Descent#
Fix all parameters except for \(\beta_j\) for some \(j \in \{1,\ldots,p\}\). As a function of \(\beta_j\), the average negative log likelihood is,
where
and where \(c\) is constant with respect to \(\beta_j\).
This is just a scalar minimization problem. Completing the square, we can rewrite the objective as,
Exercise
Solve for \(\mu_j\) and \(\sigma_j^2\).
Answer
First, expand the objective as
where
Then expand \((\beta_j - \mu_j)^2 / \sigma_j^2\) to see that,
mus = [-2, -1.0, 0.0, 0.5, 1.5]
sigmasq_lmbda = 1.0
betas = torch.linspace(-2, 2, 101)
fig, axs = plt.subplots(1, len(mus), figsize=(3 * len(mus), 3))
for k, (mu, ax) in enumerate(zip(mus, axs)):
L = 0.5 * (mu - betas)**2 + sigmasq_lmbda * torch.abs(betas)
ax.plot(betas, L)
ax.axvline(betas[torch.argmin(L)], color="r", linestyle=":")
ax.set_title(rf"$\mu_j={mu:.1f}$")
ax.set_xlabel(r"$\beta_j$")
ax.set_xlim(-2, 2)
if k == 0: ax.set_ylabel(r"$L(\beta_j; \mathbf{\beta}_{\neg j})$")
plt.tight_layout()

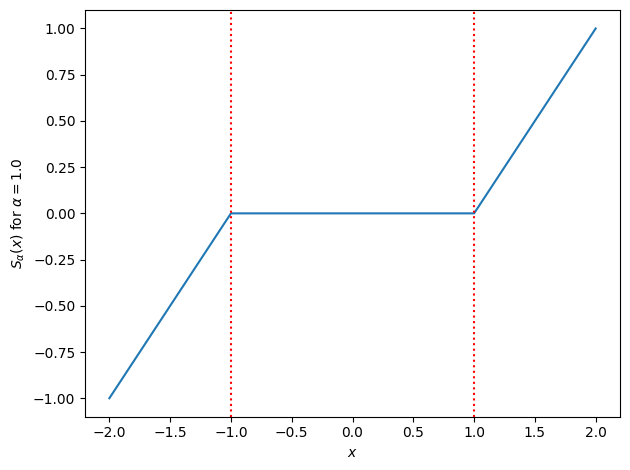
Note that many of the minimizers (denoted by the red lines) are obtained at \(\beta_j = 0\)! With a bit of calculus, we can show that the minimizer is given by the soft-thresholding operator,
We can write the soft-thresholding operator more compactly as,
Let’s plot it below.
def soft_threshold(x: Float[Tensor, "..."],
alpha: float) \
-> Float[Tensor, "..."]:
"""Compute the soft-thresholding operator with argument `x` and threshold `alpha`.
"""
return torch.sign(x) * torch.maximum(torch.abs(x) - alpha, torch.zeros_like(x))
# Plot the soft-thresholding function
xs = torch.linspace(-2, 2, 101)
alpha = 1.0
plt.plot(xs, soft_threshold(xs, alpha))
plt.xlabel(r"$x$")
plt.ylabel(rf"$S_\alpha(x)$ for $\alpha={alpha:.1f}$")
plt.axvline(alpha, color="r", linestyle=":")
plt.axvline(-alpha, color="r", linestyle=":")
plt.tight_layout()
Coordinate ascent step for the intercept#
Exercise
Show that the coordinate update for the intercept is,
where \(\widetilde{y}_{i0} = y_i - \mbx_i^\top \mbbeta\).
Weighted Lasso Regression#
Finally, suppose we have heteroskedastic noise,
where \(w_i\) is the inverse variance (precision) of the \(i\)-th observation.
Then the objective would become,
Note that the \(w_i\)’s become the weights in the objective.
Following the same steps as above, we can write the objective as a function of \(\beta_j\),
where
Again, the coordinate-wise minimum is obtained at \(\beta_j^\star = S_{\sigma_j^2 \lambda}(\mu_j)\).
For the intercept, \(\beta_0^\star = \frac{\sum_{i=1}^n w_i \widetilde{y}_{i0}}{\sum_{i=1}^n w_i}\).
Synthetic Demo#
Let’s try it out with some synthetic data. We’ll simulate data from a model with \(p=10\) dimensional covariates and unit-variance Gaussian noise (i.e., all weights are equal to 1). We’ll set some of the true weights to be exactly zero and see how well we can recover them from the noisy data.
torch.manual_seed(305 + ord('b'))
n = 100
p = 10
true_beta0 = 0.0
true_beta = Normal(0, 1).sample((p,)) * Bernoulli(0.5).sample((p,))
weights = torch.ones(n)
X = Normal(0, 1).sample((n, p))
y = Normal(X @ true_beta + true_beta0, 1 / weights).sample()
First, let’s compare the true weights to the ordinary least squares estimate.
# let's even assume we know beta0 = 0.0 for simplicity
beta_ols = torch.linalg.solve(X.T @ X, X.T @ y)
plt.axhline(0, color="k", linestyle="-")
plt.bar(torch.arange(p), true_beta, alpha=0.5, label=r"$\beta_{\mathsf{true}}$")
plt.plot(torch.arange(p), beta_ols, "rx", label=r"$\beta_{\mathsf{ols}}$")
plt.xlabel(r"feature $j$")
plt.ylabel(r"weight $\beta_j$")
plt.legend()
plt.tight_layout()
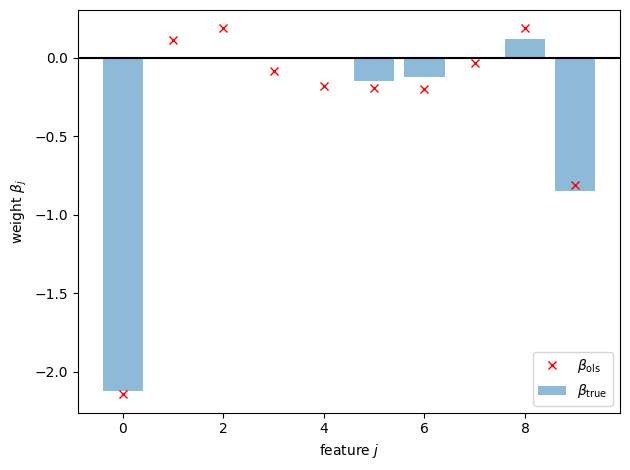
Not so good… Let’s try with the Lasso, fit using coordinate descent.
To start, let’s just pick \(\lambda = 0.1\), for no very good reason.
def coordinate_descent_step(X: Float[Tensor, "num_datapoints num_features"],
y: Float[Tensor, "num_datapoints"],
weights: Float[Tensor, "num_datapoints"],
beta0: Float[Tensor, ""],
beta: Float[Tensor, "num_features"],
lmbda: float) \
-> Tuple[Float[Tensor, ""], Float[Tensor, "num_features"]]:
"""
Perform a single step of coordinate descent for the LASSO problem.
"""
# Update the intercept
beta0 = torch.mean(weights * (y - X @ beta)) / torch.mean(weights)
# Update the coefficients
for j in range(p):
ytilde_j = y - beta0 - X @ beta + X[:, j] * beta[j]
sigmasq_j = 1 / torch.mean(weights * X[:, j]**2)
mu_j = torch.mean(weights * X[:, j] * ytilde_j) * sigmasq_j
beta[j] = soft_threshold(mu_j, lmbda * sigmasq_j)
return beta0, beta
def weighted_lasso_objective(X: Float[Tensor, "num_datapoints num_features"],
y: Float[Tensor, "num_datapoints"],
weights: Float[Tensor, "num_datapoints"],
beta0: Float[Tensor, ""],
beta: Float[Tensor, "num_features"],
lmbda: float) \
-> Float[Tensor, ""]:
"""
Compute the weighted LASSO objective function.
"""
return -Normal(X @ beta + beta0, 1 / weights).log_prob(y).mean() + lmbda * torch.norm(beta, 1)
def lasso(X: Float[Tensor, "num_datapoints num_features"],
y: Float[Tensor, "num_datapoints"],
weights: Optional[Float[Tensor, "num_datapoints"]] = None,
beta0: Optional[Float[Tensor, ""]] = None,
beta: Optional[Float[Tensor, "num_features"]] = None,
lmbda: Optional[float] = 0.,
loss_fn: Optional[Callable] = lambda *args: torch.nan,
num_iter: int = 10) \
-> Tuple[Float[Tensor, ""], Float[Tensor, "num_features"], Float[Tensor, "num_iter"]]:
"""
Perform LASSO regression using coordinate descent.
"""
n, p = X.shape
# Initialize optional parameters
if weights is None: weights = torch.ones(n)
if beta0 is None: beta0 = y.mean()
if beta is None: beta = torch.zeros(p)
losses = []
for _ in range(num_iter):
losses.append(loss_fn(X, y, weights, beta0, beta, lmbda) if loss_fn is not None else None)
beta0, beta = coordinate_descent_step(X, y, weights, beta0, beta, lmbda)
return beta0, beta, torch.as_tensor(losses)
beta0_lasso, beta_lasso, losses = lasso(X, y, weights, lmbda=0.1, loss_fn=weighted_lasso_objective)
plt.plot(losses, '-o')
plt.xlabel("iteration")
plt.ylabel(r"loss $\mathcal{L}(\beta_0, \beta)$")
plt.tight_layout()
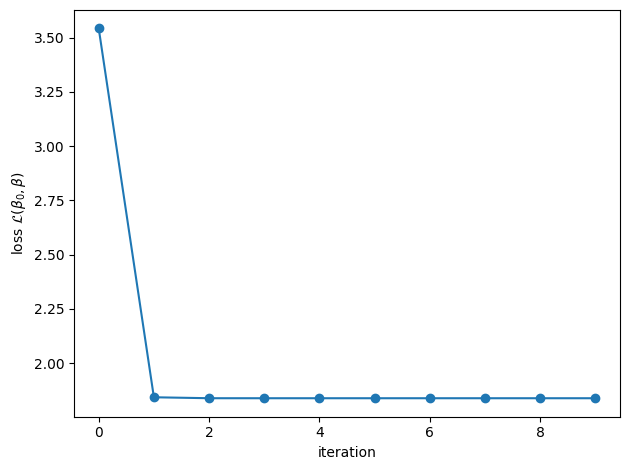
# Now plot the Lasso estimates
plt.axhline(0, color="k", linestyle="-")
plt.bar(torch.arange(p), true_beta, alpha=0.5, label=r"$\beta_{\mathsf{true}}$")
plt.plot(torch.arange(p), beta_ols, "rx", label=r"$\beta_{\mathsf{ols}}$")
plt.plot(torch.arange(p), beta_lasso, "o", color='orange', label=r"$\beta_{\mathsf{lasso}}$")
plt.xlabel(r"feature $j$")
plt.ylabel(r"weight $\beta_j$")
plt.legend()
plt.tight_layout()
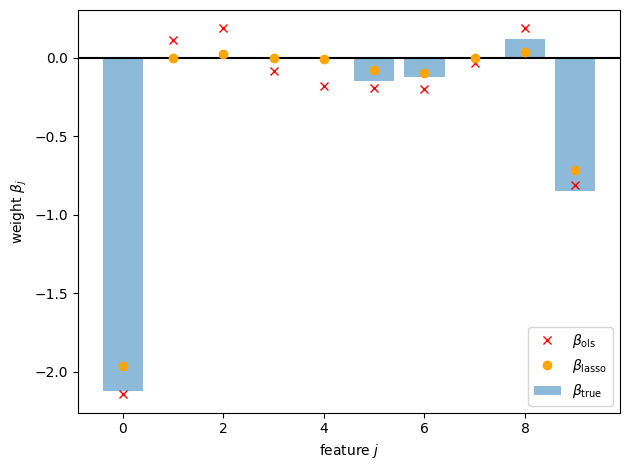
Questions
Can you identify two was in which the Lasso estimate differs from the OLS estimate?
What estimate do you get if you set \(\lambda = 0\)?
What if you take \(\lambda \to \infty\)?
Fitting Sparse GLMs#
Now let’s generalize this approach to fit \(\ell_1\)-regularized GLMs! This is exactly what the glmnet package [FHT10] solves.
Suppose we have a GLM with the canonical mean function,
where we have again factored out the intercept.
The regularized objective is,
Review: Iteratively Reweighted Least Squares#
Recall that Newton’s method for canonical GLMs (without regularization) is equivalent to iteratively reweighted least squares. The \((t+1)\)-th step of Newton’s method is equivalent to solving a weighted least squares problem to find the minimum of an objective,
where the working responses are
the predictions are,
and the weights are equal to the conditional variances,
For example, in a logistic regression,
The Algorithm#
From here, we can sketch out a pretty straightforward algorithm for fitting sparse GLMs. Within each Newton iteration, solve a weighted least squares problem, subject to the \(\ell_1\)-regularization penalty, using coordinate descent. Once the coordinate descent procedure converges, update the working responses and weights, then repeat. This is essentially the algorithm in glmnet [FHT10]!
Synthetic Demo#
Let’s try it out on some synthetic data, like above. We’ll modify the simulation to produce binary responses
torch.manual_seed(305 + ord('b'))
n = 100
p = 10
true_beta0 = 0.0
true_beta = Normal(0, 1).sample((p,)) * Bernoulli(0.5).sample((p,))
X = Normal(0, 1).sample((n, p))
y = Bernoulli(logits=X @ true_beta + true_beta0).sample()
First, we’ll fit the model with maximum likelihood estimation using scikit learn.
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(penalty='l2', C=100.0, fit_intercept=True)
lr.fit(X, y)
beta_mle = torch.tensor(lr.coef_.squeeze(), dtype=torch.float32)
plt.axhline(0, color="k", linestyle="-")
plt.bar(torch.arange(p), true_beta, alpha=0.5, label=r"$\beta_{\mathsf{true}}$")
plt.plot(torch.arange(p), beta_mle, "rx", label=r"$\beta_{\mathsf{mle}}$")
plt.xlabel(r"feature $j$")
plt.ylabel(r"weight $\beta_j$")
plt.legend()
plt.tight_layout()
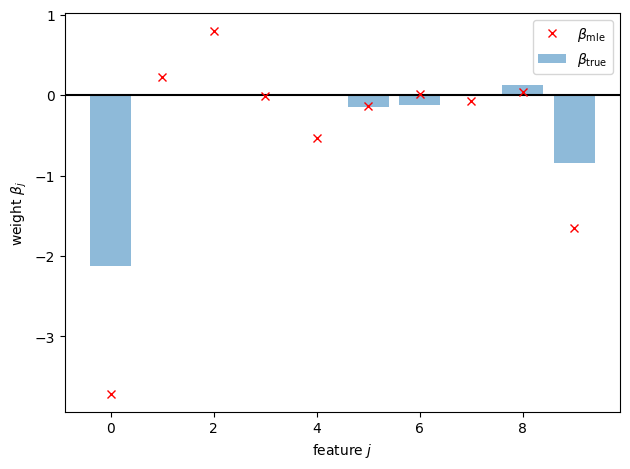
Now let’s implement the glmnet algorithm.
def logreg_lasso_objective(X: Float[Tensor, "num_datapoints num_features"],
y: Float[Tensor, "num_datapoints"],
beta0: Float[Tensor, ""],
beta: Float[Tensor, "num_features"],
lmbda: float) \
-> Float[Tensor, ""]:
"""
Compute the logistic regression LASSO objective function
"""
return -Bernoulli(logits=X @ beta + beta0).log_prob(y).mean() + lmbda * torch.norm(beta, 1)
def _glmnet_step(X: Float[Tensor, "num_datapoints num_features"],
y: Float[Tensor, "num_datapoints"],
beta0: Float[Tensor, ""],
beta: Float[Tensor, "num_features"],
lmbda: float,
num_coord_ascent_steps: int=10) \
-> Tuple[Float[Tensor, ""], Float[Tensor, "num_features"]]:
"""
Solve the inner LASSO problem for a single step of the glmnet algorithm.
"""
# Compute the working responses and weights using the current parameters
yhat = torch.sigmoid(X @ beta + beta0)
weights = yhat * (1 - yhat)
z = X @ beta + beta0 + (y - yhat) / weights
# Solve the weighted lasso problem using the code above to obtain new params
beta0, beta, _ = lasso(X, z, weights,
beta0=beta0,
beta=beta,
lmbda=lmbda,
num_iter=num_coord_ascent_steps)
return beta0, beta
def glmnet(X: Float[Tensor, "num_datapoints num_features"],
y: Float[Tensor, "num_datapoints"],
beta0: Optional[Float[Tensor, ""]] = None,
beta: Optional[Float[Tensor, "num_features"]] = None,
lmbda: Optional[float] = 0.,
num_iter: int = 10,
num_coord_ascent_steps: int = 10) \
-> Tuple[Float[Tensor, ""], Float[Tensor, "num_features"], Float[Tensor, "num_iter"]]:
"""
Find the MLE of logistic regression with LASSO regularization using the glmnet algorithm.
"""
n, p = X.shape
# Initialize beta0 and beta
if beta0 is None: beta0 = torch.logit(y.mean())
if beta is None: beta = torch.zeros(p)
losses = []
for _ in range(num_iter):
losses.append(logreg_lasso_objective(X, y, beta0, beta, lmbda))
beta0, beta = _glmnet_step(X, y, beta0, beta, lmbda, num_coord_ascent_steps)
return beta0, beta, torch.as_tensor(losses)
# Run it!
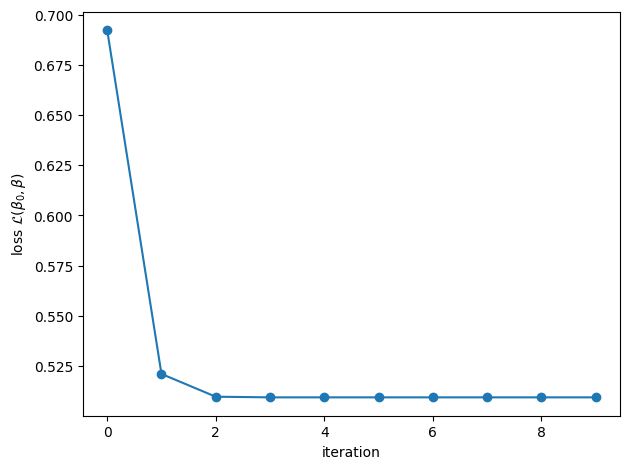
beta0_glmnet, beta_glmnet, losses = glmnet(X, y, lmbda=0.05)
plt.plot(losses, '-o')
plt.xlabel("iteration")
plt.ylabel(r"loss $\mathcal{L}(\beta_0, \beta)$")
plt.tight_layout()
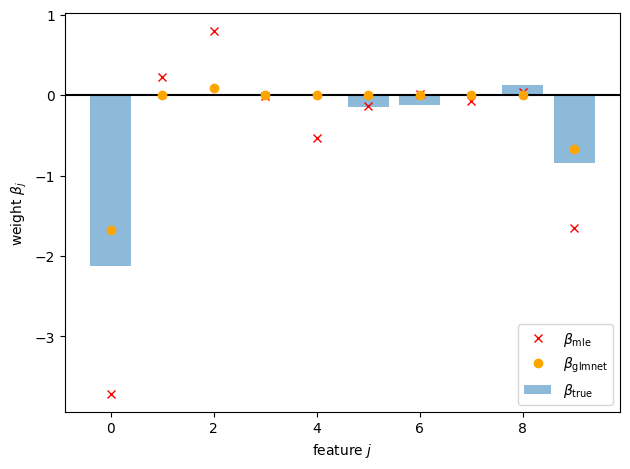
plt.axhline(0, color="k", linestyle="-")
plt.bar(torch.arange(p), true_beta, alpha=0.5, label=r"$\beta_{\mathsf{true}}$")
plt.plot(torch.arange(p), beta_mle, "rx", label=r"$\beta_{\mathsf{mle}}$")
plt.plot(torch.arange(p), beta_glmnet, "o", color="orange", label=r"$\beta_{\mathsf{glmnet}}$")
plt.xlabel(r"feature $j$")
plt.ylabel(r"weight $\beta_j$")
plt.legend()
plt.tight_layout()
Computational Tricks#
Our implementation is far from optimized, and there are several simple tricks to speed it up.
Rather than recomputing the residual for each coordinate, we can update and downdate the residual after each coordinate update.
You can show that the coordinate updates only depend on sufficient statistics \(\sum_{i} w_i x_{ij} x_{ik}\) and \(\sum_i w_i z_i x_{ij}\), and these statistics don’t change within the each outer loop. We can save some time by precomputing these at the start of the
_glmnet_stepfunction. This trick is referred to as using covariance updates.When \(X\) is sparse, we can implement the sufficient statistics calculations even more efficiently.
Friedman et al. [FHT10] describe several other implementation-level details for making the code as fast as possible. You should also check out James Yang’s thesis and his amazing adelie package for LASSO problems.
Proximal Methods#
The glmnet algorithm is intuitive, but why the heck does it work?! To gain a deeper theoretical understanding, let’s take a step back and talk about proximal methods.
Proximal Gradient Descent#
Proximal gradient descent is an optimization algorithm for convex objectives that decompose into a differentiable part and a non-differentiable part,
where \(\cL_{\mathsf{d}}\) is convex and differentiable, whereas \(\cL_{\mathsf{nd}}\) is convex but not differentiable. The idea is to stick as close to vanilla gradient descent as possible, while correcting for the non-differentiable part of the objective.
If we just had the differentiable part, \(\cL_{\mathsf{d}}\), we could perform gradient descent. One way to think about the gradient descent update is as the solution to a quadratic minimization problem,
We can think of the surrogate problem as a second order approximation of the objective in which the Hessian is replaced with \(\frac{1}{\alpha_t} \mbI\).
Proximal gradient descent follows the same logic, but it keeps the non-differentiable part,
The resulting update balances two parts:
Stay close to the vanilla gradient descent update, \(\mbbeta^{(t)} - \alpha_t \nabla \cL_{\mathsf{d}}(\mbbeta^{(t)})\).
Also minimize the non-differentiable part of the objective, \(\cL_{\mathsf{nd}}(\mbbeta^{(t)})\).
As a sanity check, note that we recover vanilla gradient descent with \(\cL_{\mathsf{nd}}(\mbbeta^{(t)}) = 0\).
Proximal Mapping#
We call the function,
the proximal mapping.
Notes
The proximal mapping depends on the form of the non-differentiable part of the objective, even though we have suppressed that in the notation.
However, it does not depend on the form of the continuous part of the objective.
Algorithm#
With this definition, the proximal gradient descent algorithm is,
Algorithm 1 (Proximal Gradient Descent)
Input: Initial parameters \(\mbbeta^{(0)}\), proximal mapping \(\mathrm{prox}(\cdot; \cdot)\).
For \(t=1,\ldots, T\)
Set \(\mbbeta^{(t)} \leftarrow \mathrm{prox}(\mbbeta^{(t-1)} - \alpha_t \nabla \cL_{\mathsf{d}}(\mbbeta^{(t-1)}); \alpha_t)\).
Return \(\mbbeta^{(T)}\).
So far, it’s not obvious that this framing is helpful. We still have a potentially challenging optimization problem to solve in computing the proximal mapping. However, for many problems of interest, the proximal mapping has simpled closed solutions.
Proximal Gradient Descent for Lasso Regression#
Consider the Lasso problem. The objective decomposes into convex differentiable and non-differentiable parts,
Proximal Mapping#
The proximal mapping is,
It separates into optimization problems for each coordinate, and each coordinate has a closed-form solution in terms of the soft-thresholding operator!
Iterative Soft-Thresholding Algorithm#
Now let’s plug in the gradient of the differentiable part,
Substituting this into the proximal gradient descent algorithm yields what is sometimes called the iterative soft-thresholding algorithm (ISTA),
Algorithm 2 (Iterative Soft-Thresholding)
Input: Initial parameters \(\mbbeta^{(0)}\), covariates \(\mbX \in \reals^{n \times p}\), responses \(\mby \in \reals^n\)
For \(t=1,\ldots, T\)
Set \(\mbbeta^{(t)} \leftarrow S_{\alpha_t \lambda}(\mbbeta^{(t-1)} - \alpha_t \mbX^\top (\mby - \mbX \mbbeta^{(t-1)}))\).
Return \(\mbbeta^{(T)}\).
Convergence#
If \(\nabla \cL_{\mathsf{d}}\) is \(L\)-smooth then proximal gradient descent with fixed step size \(\alpha_t = 1/L\) then,
so it matches the gradient descent convergence rate of \(\cO(1/\epsilon)\). (With Nesterov’s accelerated gradient techniques, you can speed this up to \(\cO(1/\sqrt{\epsilon})\).
Proximal Newton Method#
One great thing about proximal gradient descent is its generality. We could easily apply it to \(\ell_1\)-regularized GLMs, substituting the gradient of the negative log likelihood, which also has a simple closed form expression. The proximal operator remains the same, and we obtain the same converge rates as gradient descent on standard GLMs.
However, we saw that Newton’s method yielded significantly faster convergence rates of \(\cO(\log \log \frac{1}{\epsilon})\). Can we obtain similar performance for \(\ell_1\)-regularized GLMs?
To obtain a proximal Newton method, we proceed in the same fashion as above, but rather than approximating the second order term with \(\alpha_t^{-1} \mbI\), we will use the Hessian of \(\cL_{\mathsf{d}}\). That leads to a proximal mapping of the form,
where \(\|\mbx \|_{\mbH_t}^2 = \mbx^\top \mbH_t \mbx\) is a squared norm induced by the positive definite matrix \(\mbH_t\).
Note
Note that proximal mapping for proximal gradient descent corresponds to the special case in which \(\mbH_t = \frac{1}{\alpha_t} \mbI\).
Let \(\mbg_t = \nabla \cL_{\mathsf{d}}(\mbbeta^{(t)})\) and \(\mbH_t = \nabla^2 \cL_{\mathsf{d}}(\mbbeta^{(t)})\) denote the gradient and Hessian, respectively. The undamped proximal Newton update is,
As with Newton’s method, however, we often need to use damped updates,
with step size \(\alpha_t \in [0, 1]\).
The challenge, as we will see below, is that solving the proximal Newton mapping can be more challenging.
Proximal Newton for Sparse GLMs#
Let’s consider the proximal Newton mapping for \(\ell_1\)-regularized GLMs, like logistic regression. Here, the non-differentiable part of the objective is \(\cL_{\mathsf{nd}}(\mbbeta) = \lambda \|\mbbeta\|_1\). Unfortunately, the proximal Newton update no longer has a closed form solution because when we introduce the Hessian, the problem no longer separates across coordinates since the Hessian is generally not diagonal.
However, note that the proximal Newton step minimizes a second-order Taylor approximation of the log likelihood plus an \(\ell_1\)-regularization penalty,
This is exactly the same problem in the inner loop of the glmnet algorithm! In particular, we can view the second-order Taylor approximation of the log likelihood as a weighted least squares objective with working responses and weights. We can solve that inner problem with coordinate ascent, just like above.
TL;DR: the intuitive algorithm we derived above is really a proximal Newton algorithm.
Caveats#
As with regular Newton’s method, proximal Newton exhibits local quadratic convergence to obtain error \(\epsilon\) in \(\cO(\log \log 1/\epsilon)\) iterations. Though here, each iteration requires an inner coordinate descent loop to solve the proximal mapping.
Note
In practice, you may need to also implement a backtracking line search to choose the step size \(\alpha_t\), since you may not start in the local quadratic regime. Logistic regression with decent initialization is reasonably well behaved, but Poisson regression with log link functions can be sensitive.
Conclusion#
The proximal methods disussed today are what run behind the scenes of modern packages for sparse linear and logistic regression. In particular, sklearn.linear_model.Lasso uses a fast coordinate descent algorithm like discussed above, and GLMNet [FHT10] uses a proximal Newton algorithm with coordinate descent for the proximal step.