RNNs are natural models for sequential data, but the time complexity of evaluation and backpropagating gradients is a severe limitation. In modern machine learning, one of the deciding factors is how many training epochs you can perform for a fixed computational budget. To that end, architectures that can process an entire sequence in parallel are advantageous. Transformers are one such architecture.
Transformers underlie large language models (LLMs) like Open AI’s ChatGPT and Google’s Gemini. They are also widely used in computer vision and other domains of machine learning. This chapter walks through the basic building blocks of a transformer: self-attention, token-wise nonlinear transformations, layer norm, and positional encodings. We follow the presentation of Turner (2023) with some modifications for consistency with these notes.
Preliminaries¶
Tokenization¶
Before a transformer can process text, the raw string must be converted into a sequence of discrete tokens drawn from a finite vocabulary . The choice of tokenization scheme involves a tradeoff: word-level tokenization yields short sequences but requires a very large vocabulary and cannot handle unknown words; character-level tokenization handles any input but produces very long sequences that stress the attention cost.
Modern LLMs use subword tokenization, which decomposes text into vocabulary units that are between characters and words in granularity. The dominant algorithm is Byte Pair Encoding (BPE) Sennrich et al., 2016, which starts from a character vocabulary and iteratively merges the most frequent adjacent pair of symbols until the vocabulary reaches a target size (typically 32k–128k tokens). Common words become single tokens; rare words are split into subword pieces. Because BPE operates on bytes, it handles any Unicode text without unknown-token issues.
Each discrete token index is then mapped to a continuous vector via a learned embedding matrix , giving .
Let denote the matrix of token embeddings with as its -th row.
The output of the transformer will be another matrix of the same shape, . These output features can be used for downstream tasks like sentiment classification, machine translation, or autoregressive modeling.
The output results from a stack of transformer blocks,
Each block consists of two stages: one that operates vertically, combining information across the sequence length; another that operates horizontally, combining information across feature dimensions.
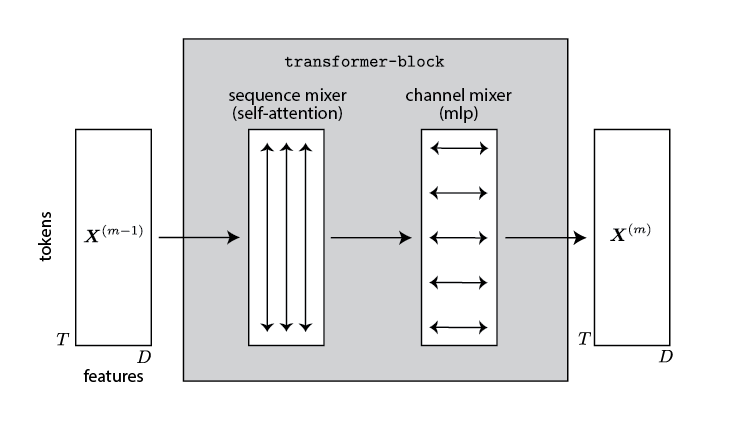
Attention¶
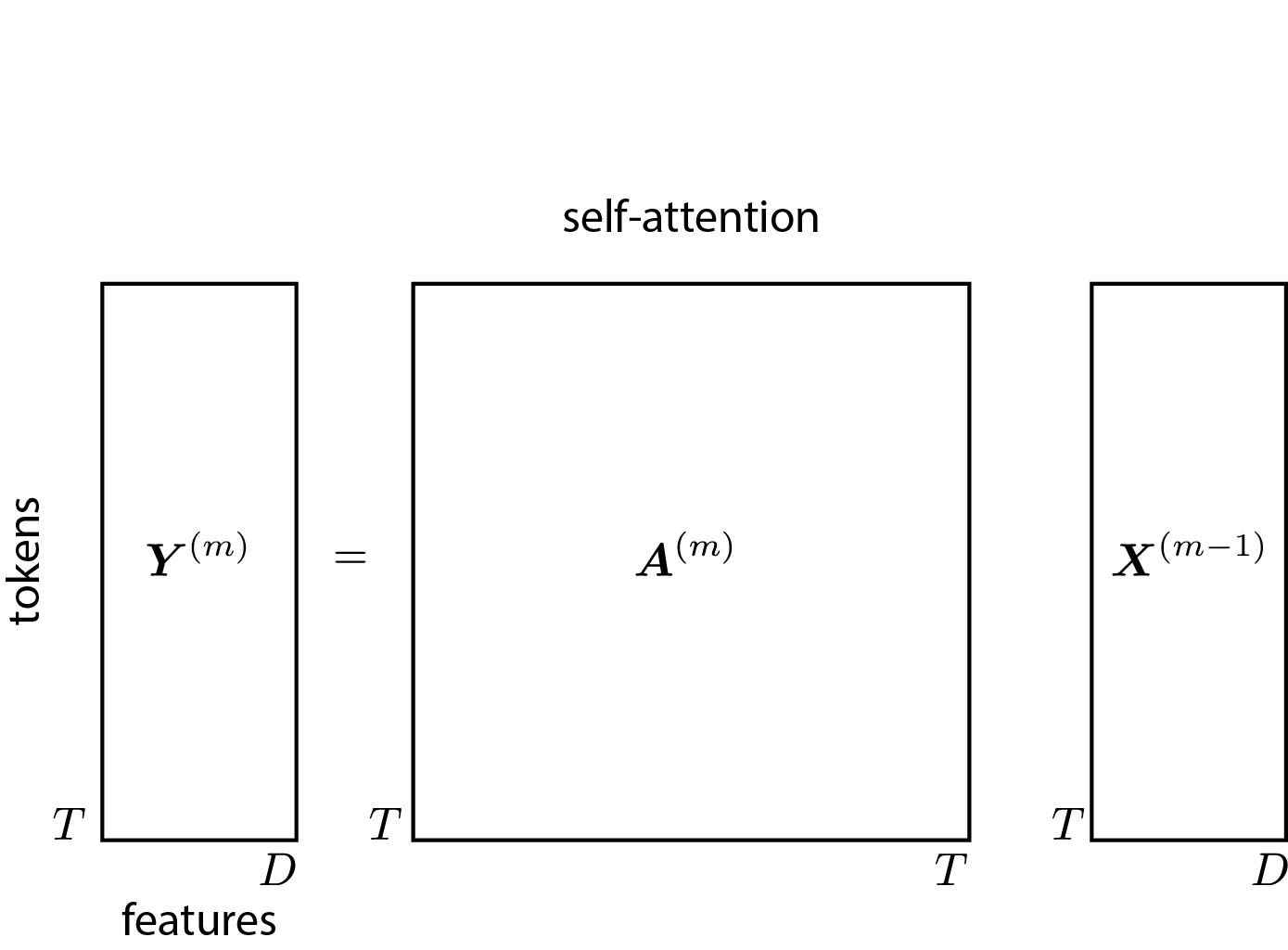
The first stage combines information across sequence length using a mechanism called attention. Mathematically, attention is a weighted average,
where is a row-stochastic attention matrix: for all . Intuitively, indicates how much output location attends to input location .
When using transformers for autoregressive sequence modeling, we constrain the attention matrix to be causal by requiring for all — i.e., the matrix is lower triangular.
Self-Attention¶
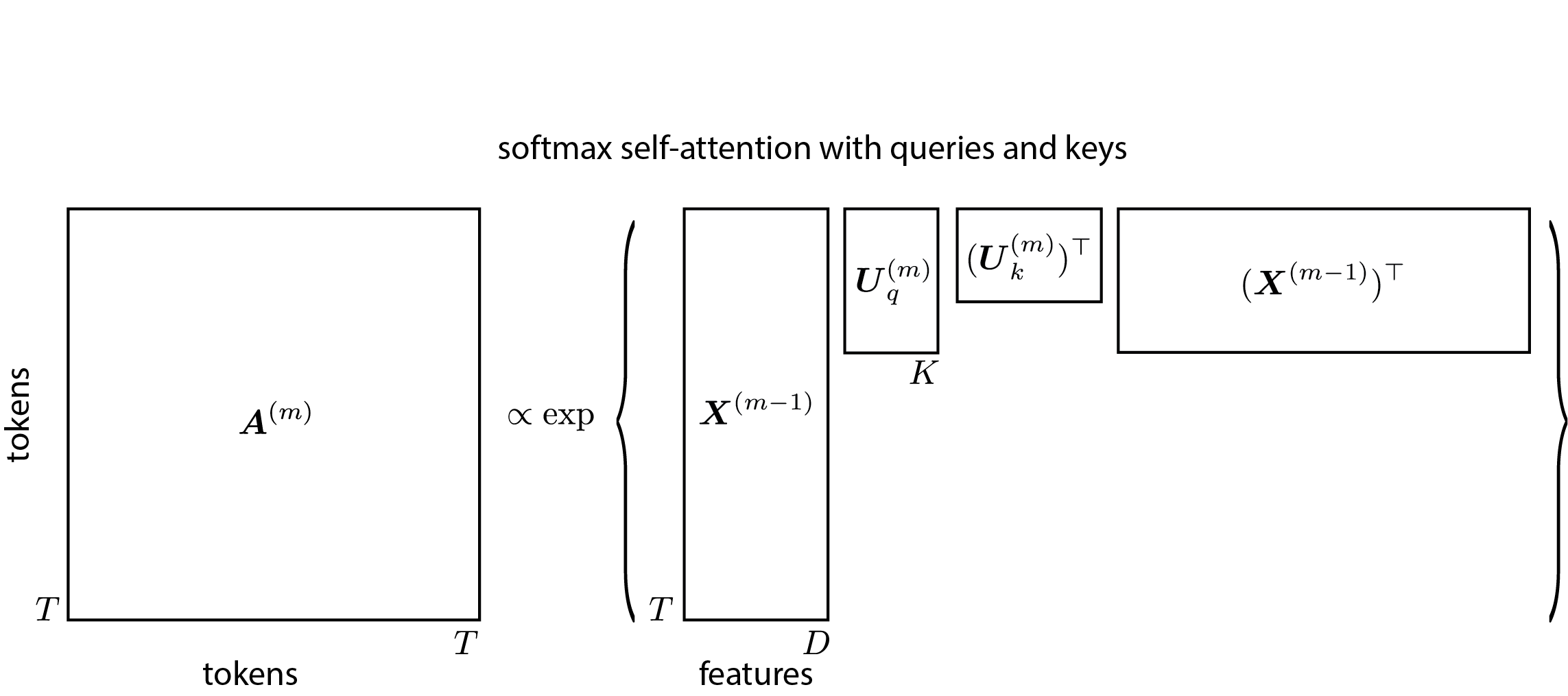
Where does the attention matrix come from? In a transformer, the attention weights are determined by the pairwise similarity of tokens in the sequence. The simplest instantiation would be
(We drop the superscript for clarity in this section.)
In practice, different feature dimensions convey different kinds of information. Transformers use separate linear projections for the queries and keys:
where are the queries, are the keys, and the factor prevents the dot products from growing large in magnitude Vaswani et al., 2017.
The KV Cache¶
During autoregressive generation, the model produces one token at a time. At step , all keys and values for were already computed at previous steps. Rather than recomputing them, an efficient implementation stores them in a KV cache and retrieves them when generating each new token. This reduces the per-step cost from to , but the cache grows linearly with context length — a key memory bottleneck at inference time.
Multi-Headed Self-Attention¶
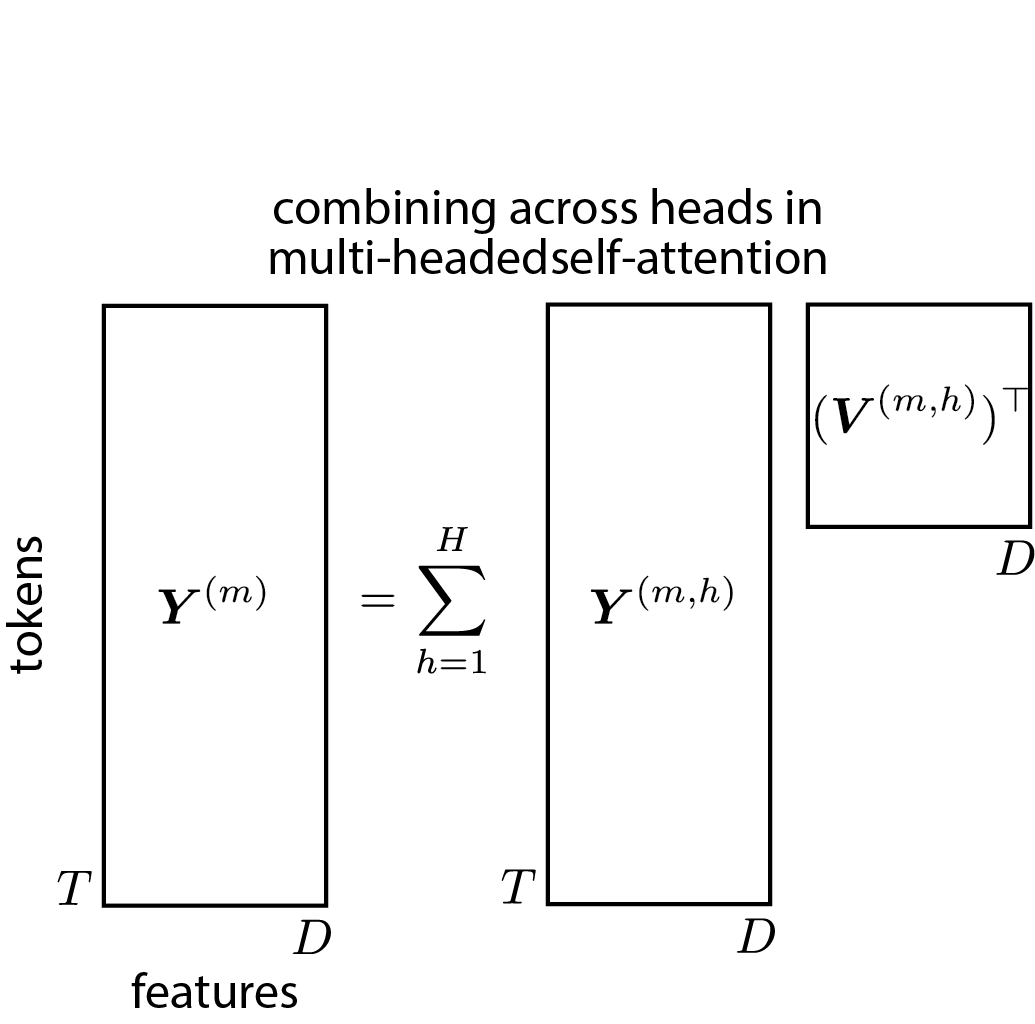
Just as a CNN uses a bank of filters in parallel, a transformer block uses attention heads in parallel. Let
where
for . The outputs are projected and summed:
where maps each head’s output back to the token dimension.
Head dimension in practice
The standard convention is , so the per-head query/key/value dimension is much smaller than the full token dimension. In Qwen3-8B Qwen Team, 2025, for example, , , giving — a factor of 32 smaller than . This keeps the total Q, K, and V parameter count at , the same as a single projection regardless of how many heads are used. It also means each head’s read and write operations on the residual stream are genuinely low-rank: the head projects the -dimensional stream down to dimensions to compute attention, then projects the result back up.
Token-wise Nonlinearity¶
After the multi-headed self-attention step, the transformer applies a token-wise nonlinear transformation to mix feature dimensions. This is done with a feedforward network applied identically at each position,
Mixture of Experts¶
A mixture of experts (MoE) layer replaces the single MLP at each transformer block with independent “expert” MLPs and a learned router that selects a sparse subset of them for each token Shazeer et al., 2017. Given a token , the router computes a probability over experts,
and routes the token to the top- experts (typically or ):
Because only experts are active per token, the computation per token is the same as a dense model with a single MLP — but the total number of parameters scales with . This decoupling of parameter count from compute allows MoE models to reach much higher capacity for the same training FLOP budget. Fedus et al. (2022) showed that even (routing each token to a single expert) works well at scale; modern deployments such as Mixtral 8×7B use experts with . The main practical challenges are load balancing (ensuring tokens are spread roughly evenly across experts, typically enforced with an auxiliary loss) and the communication overhead of routing tokens to different devices in a distributed setting.
Layer Norm¶
LayerNorm stabilizes training by z-scoring each token and applying a learned shift and scale:
where are learned parameters. LayerNorm is applied before each sub-layer (Pre-LN), which yields more stable training than the original Post-LN design:
This defines one . A transformer stacks such blocks to produce a deep sequence-to-sequence model.
The Residual Stream¶
The residual connections in a transformer — introduced as an optimization technique in He et al. (2016) — have a deeper architectural interpretation. Writing out the full forward pass,
reveals that every component — every attention head and every MLP — adds its output directly onto a shared residual stream that begins as the token embedding and accumulates updates across all layers Elhage et al., 2021.
This perspective has several consequences:
All components read from and write to the same space. Attention heads and MLPs interact not through layer boundaries but through their shared updates to the stream. One head can write information that a later head in a different layer reads directly.
Each head is a low-rank read-write. With the Q/K/V/O factorization, each attention head reads from the stream via and , computes an update, and writes it back via — a rank- operation on the -dimensional stream.
Residuals are structural, not incidental. The residual stream framing is the foundation of mechanistic interpretability: by analyzing which subspaces different heads and MLPs read from and write to, researchers have identified circuits that implement specific algorithms (induction, copying, retrieval) inside trained transformers.
Positional Encodings¶
Without explicit position information, a transformer treats its inputs as an unordered set of tokens — the architecture is permutation-equivariant (subject only to the causal mask). When the data have spatial or temporal structure, position must be injected explicitly.
Absolute Positional Encodings¶
The original transformer adds a fixed position vector to each token embedding:
where encodes the position using sinusoidal basis functions Vaswani et al., 2017. Learned absolute position embeddings are also common.
Rotary Position Embeddings (RoPE)¶
Absolute encodings bake position into the token embedding before the attention computation, which limits the model’s ability to generalize to sequence lengths unseen during training. Rotary Position Embeddings (RoPE) Su et al., 2024 instead encode position directly into the query–key dot product by rotating query and key vectors before the inner product.
Concretely, partition the -dimensional query and key into pairs of consecutive dimensions. For pair , define the rotation matrix,
with base frequencies for a large base (commonly ). Apply these rotations elementwise to the query and key before computing attention weights:
Because , the dot product depends only on the relative position . This relative-position property makes RoPE extrapolate more gracefully to longer sequences than absolute encodings. RoPE is now the dominant positional encoding in open-weight LLMs (LLaMA, Mistral, Qwen, Gemma).
Autoregressive Modeling¶
To use a transformer for autoregressive modeling, predictions are read from the final layer’s representations. To predict the next token label given past tokens :
where is the unembedding matrix. Like hidden states in an RNN, the final-layer representations aggregate information from all tokens up to index .
Training¶
Standard practice is to use the AdamW optimizer with gradient clipping, a warmup-then-cosine learning rate schedule, and dropout. Treat these as hyperparameters; the optimal settings are model- and data-dependent.
Scaling Laws¶
One of the most practically useful findings in LLM research is that validation loss follows power-law scaling in model size (number of parameters) and dataset size (number of training tokens) Kaplan et al., 2020. The loss decreases smoothly as either resource grows, with the two contributions approximately additive — meaning a bottleneck on one resource cannot be compensated by adding more of another.
An immediate consequence is that for a fixed compute budget FLOPs, there is an optimal allocation between model size and training tokens. Kaplan et al. (2020) initially argued that model size should be prioritized, leading to the practice of training large models on relatively few tokens. Hoffmann et al. (2022) revisited this with more careful experiments and found that model size and training tokens should scale in roughly equal proportion: the Chinchilla result is that the compute-optimal number of training tokens is approximately . Concretely, a 7B-parameter model trained compute-optimally should see around 140B tokens — much more data than earlier models of comparable size used.
This has had an outsized practical impact: post-Chinchilla models (LLaMA and its successors) train smaller models on far more data than pre-Chinchilla norms, achieving better performance at inference time for the same training compute.
Open-Weight LLMs¶
The transformer landscape is evolving too rapidly for any static summary to remain useful for long. That said, students interested in working with LLMs directly have access to a growing ecosystem of high-quality open-weight models — models whose weights are publicly released even if training details are not always fully disclosed. Current families worth being aware of include Meta’s LLaMA series Touvron et al., 2023Grattafiori et al., 2024, Mistral AI’s Mistral and Mixtral models Jiang et al., 2023Jiang et al., 2024, Google’s Gemma family Gemma Team, 2024, and Alibaba’s Qwen series. These span a range of sizes (1B–405B parameters) and are available through Hugging Face, Ollama, and similar platforms. All of them implement the core building blocks described in this chapter — Pre-LN, RoPE, GQA, and SwiGLU — with the main differences lying in scale, training data, and fine-tuning for instruction following.
Conclusion¶
Transformers achieve parallelism over a full sequence by replacing the sequential hidden-state recursion with multi-headed self-attention: each token directly attends to all previous tokens, enabling gradient information to flow in a single step rather than through chained Jacobians. Viewing the architecture through the lens of the residual stream clarifies that attention heads and MLPs all operate on a shared representational space, with each component contributing a low-rank additive update. The quadratic cost of softmax attention is a practical bottleneck for long sequences and has motivated substantial recent work on more efficient alternatives.
- Turner, R. E. (2023). An Introduction to Transformers. arXiv Preprint arXiv:2304.10557.
- Sennrich, R., Haddow, B., & Birch, A. (2016). Neural Machine Translation of Rare Words with Subword Units. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 1715–1725.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is All You Need. Advances in Neural Information Processing Systems, 30.
- Qwen Team. (2025). Qwen3 Technical Report. arXiv Preprint arXiv:2505.09388.
- Ainslie, J., Lee-Thorp, J., de Jong, M., Zeiler, M., & Sanghai, S. (2023). GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 4895–4901.
- Shazeer, N. (2020). GLU Variants Improve Transformer. arXiv Preprint arXiv:2002.05202.
- Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., & Dean, J. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. International Conference on Learning Representations.
- Fedus, W., Zoph, B., & Shazeer, N. (2022). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. Journal of Machine Learning Research, 23(1), 5232–5270.
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778.
- Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., & others. (2021). A Mathematical Framework for Transformer Circuits. Transformer Circuits Thread.
- Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., & Liu, Y. (2024). RoFormer: Enhanced Transformer with Rotary Position Embedding. Neurocomputing, 568, 127063.
- Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., & Amodei, D. (2020). Scaling Laws for Neural Language Models. arXiv Preprint arXiv:2001.08361.
- Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. de L., Hendricks, L. A., Welbl, J., Clark, A., & others. (2022). Training Compute-Optimal Large Language Models. Advances in Neural Information Processing Systems, 35, 30016–30030.
- Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., & others. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv Preprint arXiv:2307.09288.
- Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Keskar, A., & others. (2024). The Llama 3 Herd of Models. arXiv Preprint arXiv:2407.21783.